Go 是一门编译性语言 (在代码运行之前需要编译成二进制机器码), 它的编译速度很快( 即便在项目中使用 go run main.go 调试代码也很少在意它的编译过程 ),
它支持在不同系统上交叉编译 ( 同事的 win 机子也不用装虚拟机了 ),
编译后几乎不对运行环境产生依赖 ( 环境部署在使用 Python 时是个很头疼的问题,虽然有很多环境管理工具,但最后还得依赖 Docker 来控制系统环境带来的影响 ),
Go 语言编译器源码在 src/cmd/compile 目录中,Go 的编译在逻辑上分为四个阶段:
- 词法与语法分析
- 类型检测和 AST 转换
- 通用 SSA 生成
- 机器码生成
接下来我们将从上述四个方面进行学习 Go 的编译过程:
词法与语法分析
这个阶段主要是对源代码进行标记(词法分析),解析(语法分析),并为对每个源文件构建成语法树 (SourceFile) 结构。 语法树结构化的描述了源文件中的每个元素(表达式、声明、语句等); 语法树还描述了文件的位置(用于错误报告、调试信息创建)。
这个阶段的代码在:
cmd/compile/internal/syntax
我们观察 syntax.Parse
这个函数基本描述了词法与语法解析器的分析过程
# 这里的 File 便是文件语法树, Parse 函数返回了 语法树与编译中的异常
func Parse(base *PosBase, src io.Reader, errh ErrorHandler, pragh PragmaHandler, mode Mode) (_ *File, first error) {
defer func() {
if p := recover(); p != nil { // 区分 panic, 若是语法错误,则 返回语法错误, 若是函数执行错误, 则继续 panic
if err, ok := p.(Error); ok {
first = err // 解析过程中的语法错误, 捕捉 panic ,转化为函数error
return
}
panic(p) // 继续 panic
}
}()
var p parser
p.init(base, src, errh, pragh, mode) // 初始化解析器
p.next() // 解析器 继承于 scanner (词法解析器), next() 完成了 词法解析的过程
return p.fileOrNil(), p.first // 解析文件(过程中进行了 语法分析), 并生成语法树(AST)
}
我们观察 syntax.parser
可以发现 syntax 继承了 scanner (词法解析器), syntax.Parse 中 p.next() 实际上执行了 scanner.next() 完成了词法解析的过程。
type parser struct {
...
scanner // parser 继承了 scanner
...
first error // 解析过程中遇到的第一个错误
...
}
下面我们学习 词法分析部分
词法分析
所有的编译过程都是从解析源文件代码开始的。词法分析的作用就是解析源代码文件, 将文件中的字符串转换成 Token 序列,方便后面的处理与解析。 而解析词法分析的程序被称作为词法解析器 (Lexer)。 而解析的过程类似于我们学习英语时候区分动词、名次、形容词, 句号,逗号,分号 ... 的过程。
src/cmd/compile/internal/syntax/scanner.go
文件中的 scanner 结构体实现了 Go 的词法解析器。
type scanner struct {
source // 文件抽象
mode uint // 启用的模式
nlsemi bool
// current token, valid after calling next()
line, col uint // 当前的行,列数
tok token // 当前被扫描到的 Token
}
src/cmd/compile/internal/syntax/tokens.go 文件则定义了 Go 语言支持的 Token 类型,所有的 Token 都被定义为 int 类型,
用于区分代码中每个元素的含义。
const (
_ token = iota
_EOF // EOF
_Name // name
_Literal // literal
_Operator // op
_AssignOp // op=
_IncOp // opop
_Assign // =
_Define // :=
...
_Lparen // (
_Lbrack // [
_Lbrace // {
...
_Go // go
_Goto // goto
_If // if
_Import // import
_Interface // interface
_Map // map
...
)
我们再来看 scanner.next 函数 (也就是 syntax.Parse 调用的 p.next()函数 ), 它用来读取代码中的下一个单词 解析成 Token, 这个函数又一个巨大的
switch/case 组成,
将 Go 常用的关键词、符号 解析成相应的Token。
func (s *scanner) next() {
nlsemi := s.nlsemi // 是否是换行
s.nlsemi = false
c := s.getr() // 获取下一个单词(符号, 空白), 若是空白 则跳过
for c == ' ' || c == '\t' || c == '\n' && !nlsemi || c == '\r' {
c = s.getr()
}
s.line, s.col = s.source.line0, s.source.col0 // 获取文件读取的行列
if isLetter(c) || c >= utf8.RuneSelf && s.isIdentRune(c, true) { // 不是符号是单词
s.ident() // 识别该单词对应的 Token
return
}
switch c { // 巨大的 switch 判断各种符号 的 Token
case -1:
if nlsemi { // 如果是行结束 标记行结束
s.lit = "EOF"
s.tok = _Semi
break
}
s.tok = _EOF // 否则 标记文件结束
case '\n': // 标记换行
s.lit = "newline"
s.tok = _Semi
case '0', '1', '2', '3', '4', '5', '6', '7', '8', '9': //标记数字
s.number(c)
...
default: // 上面的符号都没有
s.tok = 0
s.errorf("invalid character %#U", c)
goto redo // 到 最前面重新判断
}
...
通过这样一个个的标记, 我们便将代码中每个词(符号) 赋予了词意。 (有些类似于我们学习英语 区分动词、名次、形容词, 句号,逗号,分号 ... )
语法分析
语法分析是根据源语言的语法规则( 文法 Grammar )从源程序记号序列(词法分析阶段的输出 Token序列)中识别出各种语法成分,同时进行语法检查,为语义分析和代码生成做准备。
Go 语言的解释器使用 LALR(1) 的文法解析方法来解析词法分析输出的 Token 序列, 并生成抽象语法树(AST)
在本文开头观察 syntax.Parse 中我们发现 syntax.parser.fileOrNil
是语法解析的入口, 也就是文件解析, 而词法解析的结果会被保存在 scanner 中, 也就是 parser 自身。
// SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .
func (p *parser) fileOrNil() *File {
if trace { ... } // const trace = false
f := new(File)
f.pos = p.pos() // 初始化一个 File 结构体( File 实际上就是我们要的 AST语法树 )
// 文件所在的包相关信息
if !p.got(_Package) { // 守卫: 判断所有的文件都有 package
p.syntaxError("package statement must be first")
return nil
}
f.PkgName = p.name() // file node 中填入包名
p.want(_Semi)
if p.first != nil { // 守卫: 如果语法错误终止解析
return nil
}
// { ImportDecl ";" }
for p.got(_Import) { // 解析包引用
...
}
// { TopLevelDecl ";" }
for p.tok != _EOF { // 循环解析代码, 逐层构建语法树
switch p.tok {
case _Const:
...
}
}
// p.tok == _EOF
f.Lines = p.source.line // 结束文件解析
return f
其余的 Go 的文法规则的解析与定义就在 src/cmd/compile/internal/syntax/parser.go文件中。
eg: 这两个函数分别解析了 包加载 和 函数定义
// ImportSpec = [ "." | PackageName ] ImportPath .
// ImportPath = string_lit .
func (p *parser) importDecl(group *Group) Decl { ... } // import 包加载 解析
...
// FunctionDecl = "func" FunctionName ( Function | Signature ) .
// FunctionName = identifier .
// Function = Signature FunctionBody .
// MethodDecl = "func" Receiver MethodName ( Function | Signature ) .
// Receiver = Parameters .
func (p *parser) funcDeclOrNil() *FuncDecl { ... } // 函数定义 解析
...
Go 语言更详细的文法可以从
Language Specification中找到,这里包含了语言的文法、词法元素、内置函数等信息。
观察这些函数的返回值,其实返回值都继承于
syntax.Node,
其实也就是 syntax.File
(SourceTree) 的节点, 而 syntax.File 本身也继承于 syntax.Node, 它们整理之后就是一个树形结构( DeclList 可以装填多个 node )。
而 语法解析的入口函数 syntax.parser.fileOrNil 返回的就是 File。
如此,便完成了语法解析的过程。
类型检测和 AST 转换
类型检测和AST转化的主要流程在 gc.Main
这个函数中体现, 在"类型检测和AST转换" 的部分中,主要有三个过程:
- 将 语法分析中的语法树 (
syntax.Node / syntax.File) 转换成 gc 的 AST 语法树 (gc.Node) - 对新生成的AST语法树进行类型检查
- 对 AST 语法树 部分节点进行精炼优化。
然后,会对对AST进行类型检查。第一步是名称解析和类型推理,确定哪个对象属于哪个标识符,什么输入每个表达式具有的类型。类型检查包括某些额外的检查,例如 “声明且未使用”以及确定功能是否终止。
AST语法树转换
gc 包中有一个AST语法树定义
(gc.Node)
,该定义继承自早期由 C 语言版本的编译器所实现的 AST 定义。后续的代码都围绕这这个AST编写的,所以该阶段第一件事便是:
将 syntax 包的语法树定义转换成 gc 包的 AST 的形式。(额外的步骤在未来有可能会重构`)
需要澄清的是,名称“gc”代表的是“Go compiler”,与大写的“GC” (垃圾回收) 没什么关系。
我们首先观察 gc.Main
的部分代码。
func Main(archInit func(*Arch)) {
...
# L540
timings.Start("fe", "parse") // 开始解析阶段
lines := parseFiles(flag.Args()) // 开始解析文件(词法分析 + 语法分析 + AST 树转换)
timings.Stop() // 结束解析
timings.AddEvent(int64(lines), "lines") // 记录解析的行数
finishUniverse()
recordPackageName()
typecheckok = true // 类型检测开启 (关于类型检测我们在下一小结介绍)
...
}
除了 Main() 这个函数, 在这个阶段我们还需要观察一个 gc 包的全局变量 gc.xtop
xtop 是就是 AST转换后的载体 []*gc.Node
# /src/cmd/compile/internal/gc/go.go#L191
..
var xtop []*Node
...
# /src/cmd/compile/internal/gc/syntax.go#L22
type Node struct { // gc 的 AST 格式
// 树形结构
Left *Node
Right *Node
Ninit Nodes
Nbody Nodes
List Nodes
Rlist Nodes
Type *types.Type // 用于类型节点
Orig *Node // 来源节点 用于打印与跟踪
Func *Func // 用于 类函数节点
Name *Name // 用于 命名节点
Sym *types.Sym // 包与命名空间等其他信息
E interface{} // Opt or Val
...
}
再此之后,进行分析gc.parseFiles
# /src/cmd/compile/internal/gc/noder.go#L126
type noder struct { // noder 包装了 syntax.File, 为了对 syntax AST 进行其他信息的扩充
...
file *syntax.File // syntax 的 语法树
linknames []linkname
pragcgobuf [][]string
err chan syntax.Error
scope ScopeID
scopeVars []int
lastCloseScopePos syntax.Pos
}
...
# /src/cmd/compile/internal/gc/noder.go#L27
func parseFiles(filenames []string) uint {
noders := make([]*noder, 0, len(filenames)) // 初步创建一个 noder列表, noder 中包含了 syntax.File
sem := make(chan struct{}, runtime.GOMAXPROCS(0)+10)
for _, filename := range filenames { // 遍历需要解析的文件名
p := &noder{ // 初始化 noder
basemap: make(map[*syntax.PosBase]*src.PosBase),
err: make(chan syntax.Error),
}
noders = append(noders, p) // 将 noder的指针添加到noders中
go func(filename string) { // 开启一个 Goroutine 处理 当前遍历的 文件
sem <- struct{}{}
defer func() { <-sem }()
defer close(p.err)
base := syntax.NewFileBase(filename)
f, err := os.Open(filename) // 开启文件
if err != nil {
p.error(syntax.Error{Pos: syntax.MakePos(base, 0, 0), Msg: err.Error()})
return
}
defer f.Close()
// 词法语法分析, 生成 syntax语法树, 放入新创建的 noder
p.file, _ = syntax.Parse(base, f, p.error, p.pragma, syntax.CheckBranches)
}(filename)
}
var lines uint
for _, p := range noders { // 遍历刚刚创建的noders, 深层新的语法树
for e := range p.err {
p.yyerrorpos(e.Pos, "%s", e.Msg)
}
p.node() // noder() 函数中 将老得语法树 转成gc.Node 并 添加到全局变量 xtop 中
lines += p.file.Lines
p.file = nil // 释放内存
if nsyntaxerrors != 0 {
errorexit()
}
testdclstack()
}
localpkg.Height = myheight
return lines
}
接下来我们具体看看 gc.noder.node()
具体什么内容
func (p *noder) node() {
types.Block = 1
imported_unsafe = false
p.setlineno(p.file.PkgName) // 记录节点编号
mkpackage(p.file.PkgName.Value) // 设置包名
xtop = append(xtop, p.decls(p.file.DeclList)...) // 将 syntax.File 中的子树(其实就是代码中的每行代码)挨个转换成 gc.Node
...
}
syntax.File 代表了一个文件的语法树, 而它的字节点便是一块一块的代码 syntax.File.DeclList, 便是每一行的代码, 这里通过 gc.noder.decls()
函数逐个遍历文件树的每个块代码树(Declist), 我们下面分析这个过程是怎么实现的:
func (p *noder) decls(decls []syntax.Decl) (l []*Node) {
var cs constState
for _, decl := range decls {
p.setlineno(decl) // 记录节点编号
switch decl := decl.(type) { // 分类判断该行语句的语意,区分解析
case *syntax.ImportDecl: // import 加载语句
p.importDecl(decl)
case *syntax.VarDecl: // 变量定义语句
l = append(l, p.varDecl(decl)...)
case *syntax.ConstDecl: // 常量定义语句
l = append(l, p.constDecl(decl, &cs)...)
case *syntax.TypeDecl: // 类型定义语句
l = append(l, p.typeDecl(decl))
case *syntax.FuncDecl: // 函数定义语句
l = append(l, p.funcDecl(decl))
default:
panic("unhandled Decl")A // 异常
}
}
return
}
如此 通过不断的区分遍历 , 就可以将 syntax 的语法树, 转换成 gc 的语法树(保存在xtop)
类型检测
经过了AST转换, 接下来便是对 AST 进行类型检测:名称解析,类型推断,并对错误类型抛出 ( Go 除了在编译期间有类型检测, 在运行时也会进行动态类型检测, 以处理 interface 的类型转换)
我们回到 gc.Main
从 L580
至 L727 间就是关于类型检测的代码
由文档中分阶段处理AST语法树
的注释我们可以了解到,处理语法树 共分为 9 个阶段, 其中前5个阶段为类型检测阶段:
- 检查常量、类型、函数声明的类型
- 检查变量赋值语句
- 检查函数主体
- 检查闭包
- 检查内联
- 逃逸分析
- 闭包转换
- AST编译(AST转换, SSA生成,机器码生成)
- 检查外部声明。
这里并不去关注整个检测阶段,我们主要了解一下 1,2 阶段即可:
..
// L593
timings.Start("fe", "typecheck", "top1")
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op != ODCL && op != OAS && op != OAS2 && (op != ODCLTYPE || !n.Left.Name.Param.Alias) {
xtop[i] = typecheck(n, ctxStmt)
}
}
timings.Start("fe", "typecheck", "top2")
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op == ODCL || op == OAS || op == OAS2 || op == ODCLTYPE && n.Left.Name.Param.Alias {
xtop[i] = typecheck(n, ctxStmt)
}
}
...
checkMapKeys()
可以看出通过 gc.typecheck()
函数检查 常量,类型,函数声明以及变量赋值语句的类型, 但是 typecheck 中逻辑不是特别多,它主要工作就是一些类型检测之前的准备工作.
而主要逻辑都在它调用的 gc.typecheck1()
中。
typecheck1 是一个非常大的函数, 主要通过 switch/case 组成, 根据传入节点的 Op 不同, 进入不同的分支,进行检查
func typecheck1(n *Node, top int) (res *Node) {
switch n.Op {
case OTARRAY: // 切片
...
case OTMAP: // 哈希
...
case OTCHAN: // 关键字
...
}
...
return n
}
类型检查是 Go 语言编译的第二个阶段,在词法和语法分析之后我们得到了每个文件对应的抽象语法树,随后的类型检查会遍历抽象语法树中的节点,对每个节点的类型进行检验,找出其中存在的语法错误。
通用 SSA 生成
经过 AST 转换和类型检测,便来到了 SSA 生成部分.
我们先简单的了解一下 SSA:
静态单赋值形式(static single assignment form,通常简写为SSA form或是SSA)是中介码的特性,每个变量仅被赋值一次。 在原始的IR中,已存在的变量可被分割成许多不同的版本,在许多教科书当中通常会将旧的变量名称加上一个下标而成为新的变数名称, 以至于标明每个变量及其不同版本。在SSA,UD链(use-define chain,赋值代表define,使用变量代表use)是非常明确,而且每个仅包含单一元素。
SSA最主要的用途,是借由简化变数的特性,来进行简化及改进编译器最佳化的结果,举例来说:
原始代码:
y := 1
y := 2
x := y
SSA 代码:
y1 := 1
y2 := 2
x1 := y2
这样 y 就不再具有二义性。 减轻了编译器理解的复杂度。
SSA 准备与 AST 替换
SSA 准备
我们回到 'gc.Main()' 的阅读上。
func Main(archInit func(*Arch)) {
...
initssaconfig() // 初始化 ssa 配置
...
timings.Start("be", "compilefuncs") // 标记 开始 编译函数
fcount = 0
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if n.Op == ODCLFUNC {
funccompile(n) // 编译头部函数(生成 SSA)
fcount++
}
}
timings.AddEvent(fcount, "funcs")
if nsavederrors+nerrors == 0 {
fninit(xtop) // 初始化信息
}
compileFunctions() // 编译函数列表(生成 SSA)
我们先大概了解一下 gc.initssaconfig()
func initssaconfig() {
// 第一步 用 NewTypes 初始化 Types 结构体 并调用 NewPtr 缓存类型信息
types_ := ssa.NewTypes()
_ = types.NewPtr(types.Types[TINTER]) // *interface{}
...
_ = types.NewPtr(types.Errortype) // *error
// 第二步 根据当前 CPU 架构初始化 SSA 配置
ssaConfig = ssa.NewConfig(thearch.LinkArch.Name, *types_, Ctxt, Debug['N'] == 0)
...
// 初始化 一些编译器会用到的 Go 语言运行时函数
assertE2I = sysfunc("assertE2I")
assertE2I2 = sysfunc("assertE2I2")
assertI2I = sysfunc("assertI2I")
...
}
这个函数 分为三个阶段:
func NewPtr(elem *Type) *Type {
if elem == nil { Fatalf("NewPtr: pointer to elem Type is nil")} // 守卫: 验证类型不为 nil
if t := elem.Cache.ptr; t != nil { // 若已经缓存,则直接返回
if t.Elem() != elem { // 守卫:验证缓存存储的类型正确
Fatalf("NewPtr: elem mismatch")
}
return t
}
t := New(TPTR) // 创建一个类型指针 (TPTR 是个常量代表 类型指针类别 )
t.Extra = Ptr{Elem: elem} // 初始化类型指针的额外信息 (指向的类型对象)
t.Width = int64(Widthptr) // 根据指针长度配置 设置类型长度(Widthptr 在 main() 中根据环境会被设定)
t.Align = uint8(Widthptr) // 根据指针长度配置 设置类型对齐
if NewPtrCacheEnabled {
elem.Cache.ptr = t // 缓存这个类型指针
}
return t
}
NewPtr 函数的主要作用就是根据类型生成指向这些类型的指针, 同时它会根据编译器的配置将生成的指针缓存在当前类中,提高类型指针的获取效率
- 2 . 根据当前 CPU 架构初始化 SSA 配置
func NewConfig(arch string, types Types, ctxt *obj.Link, optimize bool) *Config {
c := &Config{arch: arch, Types: types} // 初始化配置
c.useAvg = true // 使用 Avg 操作优化
c.useHmul = true // 使用 Hmul 操作优化
switch arch { // 选择 CPU架构
case "amd64": // amd64 架构
c.PtrSize = 8 // 配置 指针大小
c.RegSize = 8 // ...
c.lowerBlock = rewriteBlockAMD64
c.lowerValue = rewriteValueAMD64
c.registers = registersAMD64[:]
...
case "arm64": // arm64
...
case "wasm": // wasm
default:
ctxt.Diag("arch %s not implemented", arch)
}
c.ctxt = ctxt
c.optimize = optimize
// ...
return c
}
NewConfig 会根据传入的 CPU 架构设置用于生成中间代码和机器码的函数,当前编译器使用的指针、寄存器大小、可用寄存器列表、掩码等编译选项.
所有的配置项一旦被创建,在整个编译期间都是只读的并且被全部编译阶段共享,也就是中间代码生成和机器码生成这两部分都会使用这一份配置完成自己的工作。
- 3 . 初始化 一些编译器会用到的 Go 语言运行时函数
deferproc = sysfunc("deferproc") // deferproc
...
func sysfunc(name string) *obj.LSym {
s := Runtimepkg.Lookup(name) // runtime pkg 寻找函数符号
s.SetFunc(true) // 启用
return s.Linksym() // 返回
}
至此 ssa 准备阶段结束, 完成了: 初始化类型指针; 根据环境配置 ssa 配置; 初始化编译器会用到的 runtime 包函数;
AST 替换
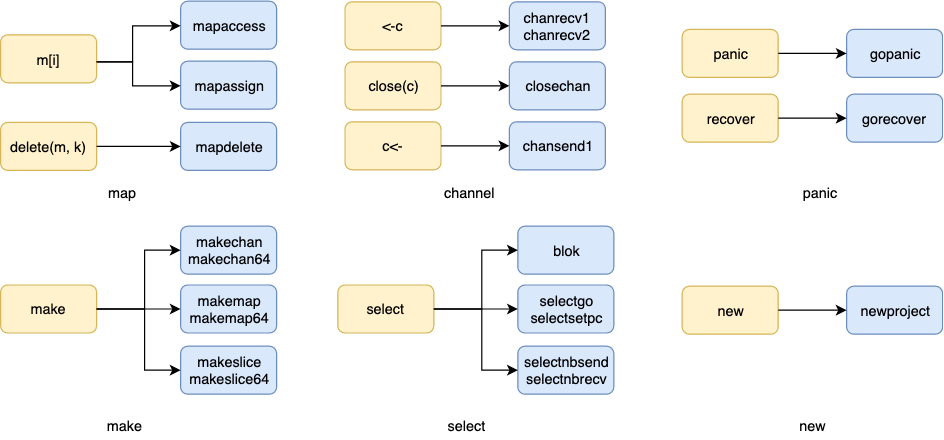
Go 语法中为用户提供了一些关键字(语法糖)方便用户开发, 比如: range, new, make, <-ch, c<-, append 等等,
这些语法在也会存在与 AST 语法树中, 但是在生成 SSA 之前, 会被编译器转换(walk)成真正的函数(或基础语法)
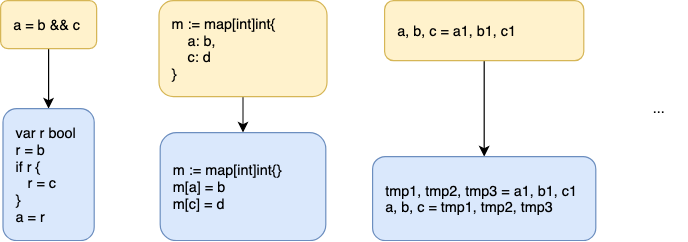
除了特别的关键字,Go 也对一些常用的语句进行了简化翻译转换(order),例如: a = b && c
... = LHS && RHS
// 转换为:
var r bool
r = LHS
if r { // or !r, for OROR
r = RHS
}
... = r
回到 gc.Main 的阅读上,我们在 处理 AST 树过程的第 8 阶段 AST 编译(L741)
可以看到这样一段函数:
func Main(archInit func(*Arc){
...
for i := 0; i < len(xtop); i++ { // 遍历树
n := xtop[i]
if n.Op == ODCLFUNC { // 若节点是操作声明函数
funccompile(n) // 函数编译
fcount++
}
}
...
}
看上去已经要进行函数编译了,我们继续阅读 gc.funccompile
func funccompile(fn *Node) {
..
if fn.Type == nil { // 守卫: 验证 fn 不为 nil
if nerrors == 0 {
Fatalf("funccompile missing type")
}
return
}
dowidth(fn.Type) // 设置类型对齐
if fn.Nbody.Len() == 0 { // 判断 fn 是否是空函数
fn.Func.initLSym(false)
emitptrargsmap(fn)
return
}
...
compile(fn) // 编译
...
}
funccompile 的目的也是在编译前,验证,处理一些编译前的准备工作
func compile(fn *Node) {
saveerrors()
order(fn) // 对函数中的每条语句进行转换(同时检查语法问题), eg:
// x = a && b =>
// var r bool; r = a;
// if r { r = b }
// x = r
if nerrors != 0 { // 判断是否有错误语句
return
}
walk(fn) // 对关键字语句进行转换
...
}
可以看出 在函数编译前,分别调用了 gc.order
和 gc.walk
对原有的AST 进行转换, 使得语法更为朴素,方便后续的 SSA生成 与 机器码编译 ( 但有些地方但也导致了一些奇怪的问题 )
我们按照顺序,从gc.order
开始
// L52
func order(fn *Node) {
if Debug['W'] > 1 { // 打印 Warning
s := fmt.Sprintf("\nbefore order %v", fn.Func.Nname.Sym)
dumplist(s, fn.Nbody)
}
orderBlock(&fn.Nbody, map[string][]*Node{}) // 在一个新的片区内整理 (并进行替换)
}
// 419
func orderBlock(n *Nodes, free map[string][]*Node) {
var order Order // 创建新 Order
order.free = free
mark := order.markTemp()
order.edge()
order.stmtList(*n) // 遍历处理
order.cleanTemp(mark) // 清楚中间临时资源
n.Set(order.out) // 用整理结果 替换原 AST
}
// 320
func (o *Order) stmtList(l Nodes) {
for _, n := range l.Slice() { // 遍历处理
o.stmt(n)
}
}
可以发现 order 目的都在 Order 工作 (这里我理解 Order 的意思是 '整理') 的准备上,
并通过 stmtList 遍历每个 statement (语句或者代码块),
而实际动作在 gc.stmt
接下来,我们大概的阅读一下 stmt 函数, 这个是一个很长的函数, 用大量的 switch/case 语句分类处理各种需要 整理 的语句 (statement), 最后再将整理好的结果放置到gc.Order.out中,
在(我们刚刚阅读的) orderBlock 的末尾,n.Set(order.out) 将结果替换到原 AST 上;
:
func (o *Order) stmt(n *Node) {
if n == nil { return } // n == nil 退出
lno := setlineno(n) // 设置行号
o.init(n) // 初始化 Order
switch n.Op { // 根据节点类型分别处理
default: // 默认报错
Fatalf("order.stmt %v", n.Op)
case OVARKILL, OVARLIVE, OINLMARK: // 三个不需要处理的类型, 直接追加
o.out = append(o.out, n)
case OAS: // Left = Right 单赋值 (这虽然是个最简单的节点,等下我们推演一下这个节点的作用)
t := o.markTemp()
n.Left = o.expr(n.Left, nil) // 处理表达式左侧 并 赋值给语句节点左侧
n.Right = o.expr(n.Right, n.Left) // 处理表达式右侧 并 赋值给语句节点右侧
o.mapAssign(n) // 处理结果追加至 o.out
o.cleanTemp(t) // 清楚临时信息
case OASOP: // x += y
...
case OAS2: // x, y, z = a, b, c
...
OAS2FUNC: // x, y = f()
...
case OAS2DOTTYPE, OAS2RECV, OAS2MAPR: // x, ok = I.(int); x, ok = <-c; x, ok = m["foo"]
...
case OBLOCK, OEMPTY: // {...} 代码块 与 空语句
...
...
case OFOR: // 三段式 for (这里就有个奇怪的地方, 在后面 关于 for range 的部分会提到)
...
case OIF: // if Ninit; Left { Nbody } else { Rlist }
}
o.exprListInPlace(n.List) // Node.List 处理
if orderBody {
orderBlock(&n.Nbody, o.free) // 递归调用 orderBlock 解析Body
}
o.out = append(o.out, n) // 追加 n
o.cleanTemp(t) // 清空缓存
我们 只分析 最简单的 OAS 节点 (使用 a := b && c 为例), 其中有个很重要的函数
gc.Order.expr
expr 用作处理赋值语句中的单个表达式(eg: 在 a := b && c 中, 就处理 a 或 b && c), 它会将解析语句时新创建的中间节点追加到 Order.out;
同时 返回 原节点解析后的变量名,
我们先 大概阅读一下 expr 代码 ( 这里为了分析 b && c 重点学习一下 OANDAND 的处理):
func (o *Order) expr(n, lhs *Node) *Node {
if n == nil { return n }
lno := setlineno(n) // 设置行号
o.init(n) // Order 初始化
switch n.Op { // 根据节点类型分别处理
default: // 默认节点
n.Left = o.expr(n.Left, nil) // 递归处理左侧
n.Right = o.expr(n.Right, nil) // 递归处理右侧
o.exprList(n.List) // 处理 Node.List
o.exprList(n.Rlist) // 处理 Node.Rlist
case OADDSTR: // + {list}
...
case OINDEXMAP: // Left[Right] map通过index读取
...
case OCONVIFACE: // Type(Left) 变量转接口类型
...
case OCONVNOP: // Type(Left) 类型转换
...
case OANDAND, OOROR: // Left && Right 和 Left || Right , 到了我们主要分析的地方
r := o.newTemp(n.Type, false) // 根据节点的Type(bool) 创建一个临时变量 r
lhs := o.expr(n.Left, nil) // 获取 Left 的结果, 赋值给 lhs
o.out = append(o.out, typecheck(nod(OAS, r, lhs), ctxStmt)) // 创建一个赋值节点(OAS; r = lhs) ,经过类型检测,最后追加到输出列表中
saveout := o.out // 创建一个变量临时保存 out 的信息
o.out = nil // 清空 out
t := o.markTemp() // 创建临时空间
o.edge() // 边缘覆盖检测 (不是很懂)
rhs := o.expr(n.Right, nil) // 获取 Right 的结果 赋值给 lhs
o.out = append(o.out, typecheck(nod(OAS, r, rhs), ctxStmt)) // 创建一个赋值节点(OAS; r = rhs) ,经过类型检测,最后追加到输出列表中
o.cleanTemp(t) // 清空临时空间
gen := o.out // 创建一个变量临时保存 out 的信息
o.out = saveout // o.out 拿回 Left 的结果
nif := nod(OIF, r, nil) // 创建 一个 if 节点 ,判断 r
if n.Op == OANDAND { // 如果 我们判断的是 && , 则在 if 节点 Nobdy 中设置 r = Right 的节点
nif.Nbody.Set(gen)
} else {
nif.Rlist.Set(gen) // 若是 || , 则在 Rlist 中设置 r = Right 节点
}
o.out = append(o.out, nif) // o.out 追加 我们刚刚构建好的 if 节点
n = r // 用 r 替换 n 节点
Case ...:
...
}
lineno = lno // 设置行号
return n // 返回 n 节点
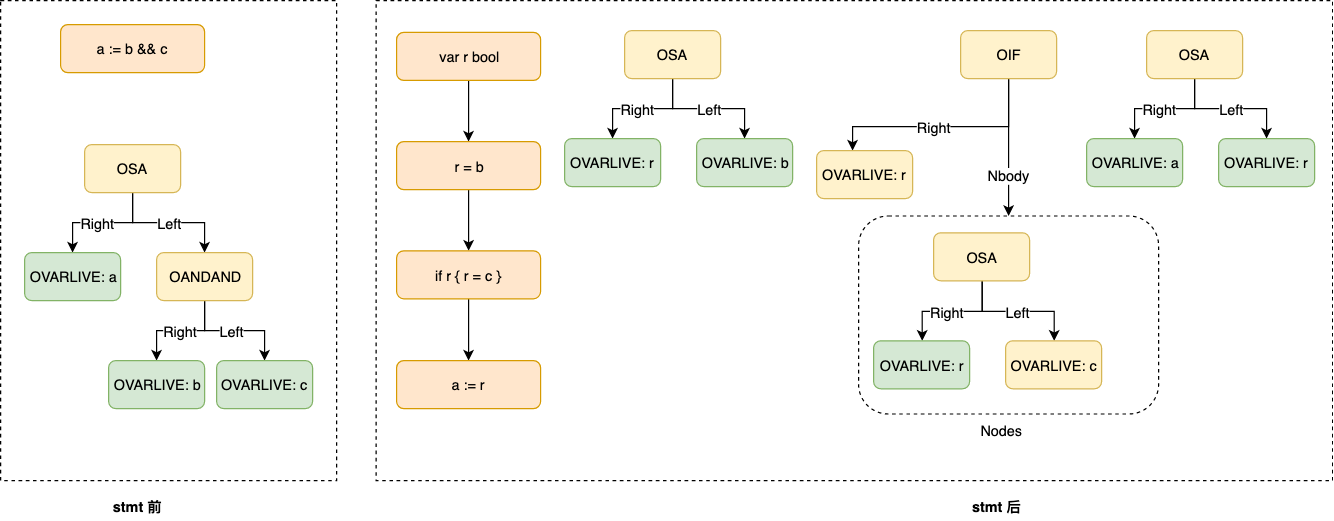
如图, 一个节点被转换成了三个节点,它们都会被添加到 Order.out 中
order 的过程主要是对代码块的初步解析,将复杂的语句,使用简单的语句代替,为后续的 walk 和 SSA 生成降低难度
接下来再看
gc.walk
, 前面提到walk 的目的主要是遍历抽象语法树的函数会将一些关键字和内建函数转换成函数调用。
func walk(fn *Node) {
Curfn = fn
... // 一些Warning打印, 和类型检测, 还有一些准备工作
walkstmtlist(Curfn.Nbody.Slice()) // 遍历函数体,进行 walk
... // warning打印等
zeroResults() // 返回值归零
heapmoves() // walk 结果 添加至 Curfn
...
}
func walkstmtlist(s []*Node) {
for i := range s { // 遍历 AST , 逐块进行 walk
s[i] = walkstmt(s[i])
}
}
而从源代码中看,整体结构也与 order 类似, gc.walk 做前期准备处理 与 后期结果赋值,
walkstmtlist
遍历每个 statement ('代码块 / 语句') 操作, 最终由
gc.walkstmt
具体分类处理:
func walkstmt(n *Node) *Node {
if n == nil { return n }
setlineno(n)
walkstmtlist(n.Ninit.Slice()) // 递归遍历 Node.Ninit
switch n.Op {
default: // 没有枚举到的语句默认为异常情况, 打印一些相关信息
if n.Op == ONAME { yyerror("%v is not a top level statement", n.Sym)
} else { yyerror("%v is not a top level statement", n.Op) }
Dump("nottop", n)
case OAS, // 一些在语句层面不用特别处理的语句 eg: xxx := xxx
...
OGETG:
...
case ORECV: ...
...
case OBLOCK:
walkstmtlist(n.List.Slice()) // 代码块 拆开 , 对内部的语句继续walk
case OIF: // if 我们观察这里, 很多语句实际上都没有做特殊处理, 只是细化,分析内部是否需要特别的 walk
n.Left = walkexpr(n.Left, &n.Ninit)
walkstmtlist(n.Nbody.Slice())
walkstmtlist(n.Rlist.Slice())
...
case OSELECT: // select 调用 walkselect 具体替换
walkselect(n)
case OSWITCH: // switch 调用 walkswitch 具体替换
walkswitch(n)
case ORANGE: // range 调用 walkrange 具体替换
n = walkrange(n)
}
return n
}
与 order 类似, walk 过程中也存在 walkexpr 来处理表达式层面 , walk 也是个很大的函数,
也是通过 巨大的 switch / case 组成
func walkexpr(n *Node, init *Nodes) *Node {
...
switch n.Op {
default:
Dump("walk", n)
Fatalf("walkexpr: switch 1 unknown op %+S", n)
case OEFACE, OAND, OSUB, OMUL, OADD, OOR, OXOR, OLSH, ORSH: // 大多数也只是细分树的层级,继续解析
n.Left = walkexpr(n.Left, init)
n.Right = walkexpr(n.Right, init)
case OLEN, OCAP: // 分析 len(Left)
if isRuneCount(n) {
// mkcall 会创建一个调用 , 在这里会调用 countrunes 函数
n = mkcall("countrunes", n.Type, init, conv(n.Left.Left, types.Types[TSTRING]))
break
}
n.Left = walkexpr(n.Left, init)
...
case OPANIC: // panic 调用 gopanic
n = mkcall("gopanic", nil, init, n.Left)
case ORECOVER: // recover 调用 gorecover
n = mkcall("gorecover", n.Type, init, nod(OADDR, nodfp, nil))
...
由此 可见 walk 过程中 在语句语法上 对 select, witch, range 等关键词进行了转换, 而 表达式层面上 对 panic, recover 等关键词进行了替换
通过 order 与 walk 共同完成了 AST转换的过程。
SSA 生成
经过 一系列 AST 转换 的过程, 语法树在结构上不再更改, 接下来就是生成 SSA 中间代码的过程。
func compile(fn *Node) {
...
order(fn)
...
walk(fn)
...
if compilenow() { // 是否立即编译
compileSSA(fn, 0) // 编译SSA
} else {
...
}
}
我们将目光转到 gc.compileSSA
func compileSSA(fn *Node, worker int) {
f := buildssa(fn, worker) // 构建 ssa.Func 结构体
...
pp := newProgs(fn, worker) // 创建指令列表对象
defer pp.Free() // 结束后释放
genssa(f, pp) // 将ssa编译成指令并追加到 pp 中
...
pp.Flush() // 生成机器码
}
最后的编译流程就是 AST —> SSA ( -> 各种SSA优化) -> 指令列表 -> 机器码
关于 SSA 的规则主要在 /src/cmd/compile/internal/ssa 中
func buildssa(fn *Node, worker int) *ssa.Func {
name := fn.funcname() // 节点名称
var astBuf *bytes.Buffer // 创建缓冲区
var s state
fe := ssafn{ // ssafn 中间对象
curfn: fn,
log: printssa && ssaDumpStdout,
}
s.curfn = fn
s.f = ssa.NewFunc(&fe) // 创建并初始化一个新 ssa.Func
s.config = ssaConfig
s.f.Type = fn.Type
s.f.Config = ssaConfig
...
s.stmtList(fn.Func.Enter) // Enter 转成 SSA , 类似于 walk 的 stmtList
s.stmtList(fn.Nbody) // 节点的内部代码转换成 SSA
ssa.Compile(s.f) // Main 转换成 SSA
return s.f
}
观察 stmtList
类似于 walk 的 stmtList, 遍历后, 通过 stmt从语句层面编译成 SSA 并将结果添加至 state
func (s *state) stmtList(l Nodes) {
for _, n := range l.Slice() {
s.stmt(n)
}
}
func (s *state) stmt(n *Node) {
... // 准备阶段
s.stmtList(n.Ninit) // 处理语句的Ninit
switch n.Op { // 巨大的 switch 根据语句的不同细分转换
case OBLOCK: // 代码块,继续遍历处理代码块内部 语句
s.stmtList(n.List)
...
case OCALLFUNC: // 函数调用
if isIntrinsicCall(n) {
s.intrinsicCall(n) // 函数调用转换
return
}
case OGO: // go
s.call(n.Left, callGo) // 生成 go ssa 节点
}
机器码生成
AST —> SSA ( -> 各种SSA优化) -> 指令列表 -> 机器码
经过 SSA 的生成, 与逐层降级,边来到了 生成指令列表和创建机器码的部分
跨平台指令列表生成
TODO 知识与精力有限,后续补充
机器码编译
Go语言源代码的 cmd/compile/internal 目录中包含了非常多机器码生成相关的包。 不同类型的 CPU 分别使用了不同的包进行生成 amd64、arm、arm64、mips、mips64、ppc64、s390x、x86 和 wasm TODO 知识与精力有限,后续补充