Go 与 协程
我们都知道线程是CPU调度的基本单位,但是由于切换时进入内核态,并且需要保存寄存器等内容,开销较大; 而协程本质是用户自行调度用户代码执行的过程,不同语言实现的方式并不相似,大致来说都是遇到阻塞的代码块后切换到其他代码块进行执行。
Go 语言在协程方面存在天生的优势,例如 Python 在 3.x 版本之后才实现异步库(asyncio)与异步语法(async/await),即便如此与发展已久的众多同步代码、仓库配合使用也会产生各种阻塞的隐患,语法使用上也存在很多问题(async 传染 等), 增加了编程者的心智负担。
而 Go 语言在创建之初,就从底层考虑并尝试解决了这个问题(天生异步), 在并发解决的问题上也几乎跳过了线程的概念(开发者几乎无感),直接使用 Goroutine 去解决,统一了并发问题的解决方式 (不再考虑多线程还是异步协程的解决途径,也不用去分是同步代码还是异步非阻塞)。
协程在不同语言中的实现并不相似,Go 语言在经过多个版本发展之后(0.x ~ 1.0 ~ 1.1 ~ 1.2 ~ 1.13 ~ 1.14 ~ 至今)才行程当前的调度器形式(MPG), 而在未来还有 "非均匀存储访问调度器提案" 等待实现。本文从最新的版本入手学习(1.14)
Scheduler
Go 的调度机制由调度器( Scheduler ) 实现,它有三个我们熟知的重要组件 MPG:
- M: Machine, 代表了机器资源,即 worker thread 、 工作线程。
- P: Processor, 处理者,一个抽象的中间层,用于调度 调度 Goroutine 在 I/O 时刻的切换。
- G: Goroutine: 我们熟知的 "Go 协程", 是 Go 语言执行任务的最小单位。(所有的 go func 都会被打包成
runtime.g)
每个 P 都持有一个 G 队列 和 正在执行的 G, P 的数量被调度器设置为 cpu 核心数 (保证最大化利用 cpu 资源), 当 P 需要执行任务的时候 会和 M 绑定,并将正在执行的 G 交给 M 去执行。当 M 执行中遇到阻塞,会创建一个新的 M, 被阻塞的 P 会移动到新的 M 上继续执行其他 G 任务。
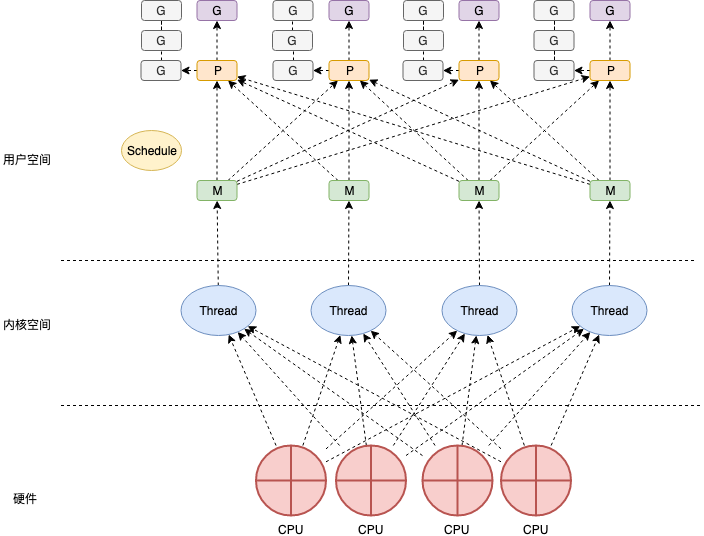
MPG 数据结构 (Scheduler 的构成)
原理讲来太空洞,我们先看一下 MPG 的数据结构, 通过其字段来窥探一下它们的作用。
MPG 的结构体都很大,定义了运行时的各种状态 (其中一部分是用来 debug),我们只从我们关心的部分入手。
先从我们最熟知的 G 开始:
G
type g struct {
stack stack // 执行栈, 描述了当前Goroutine 的栈内存范围 (lo ~ hi)
stackguard0 uintptr // 用于检测堆栈是否溢出(扩容或抢占)
stackguard1 uintptr // 用于检测C堆栈是否溢出
_panic *_panic // 指向 panic栈 最内测的对象
_defer *_defer // 指向 defer(延迟函数) 最内测的对象
m *m // 当前 Goroutine 占用的 M (可能为空)
sched gobuf // pc, sp, lr 等上下文数据
...
param unsafe.Pointer
stktopsp uintptr // sp期望栈顶, 用于回溯检查
param unsafe.Pointer // 唤醒时候传递的参数
atomicstatus uint32 // Goroutine 状态(_Gidle, _Grunnable, _Grunning ...)
stackLock uint32 // stack Lock
goid int64 // Goroutine Id 对开发者不可见,Go 团队认为引入 ID 会让部分 Goroutine 变得更特殊,从而限制语言的并发能力;
...
waitsince int64 // 阻塞的开始时间
waitreason waitReason // 阻塞的原因
preempt bool // 抢占信号
...
timer *timer // 为 time.Sleep 缓存的计时器
...
}
type stack struct { // 用于描述 Go 的执行栈
lo uintptr // 下边界
hi uintptr // 上边界
}
type gobuf struct { // 用于 保存、恢复 上下文
sp uintptr // 栈指针
pc uintptr // 程序计数器
g guintptr // 持有 gobuf 的 g 指针
ctxt unsafe.Pointer
ret sys.Uintreg // 系统调用的返回值
...
}
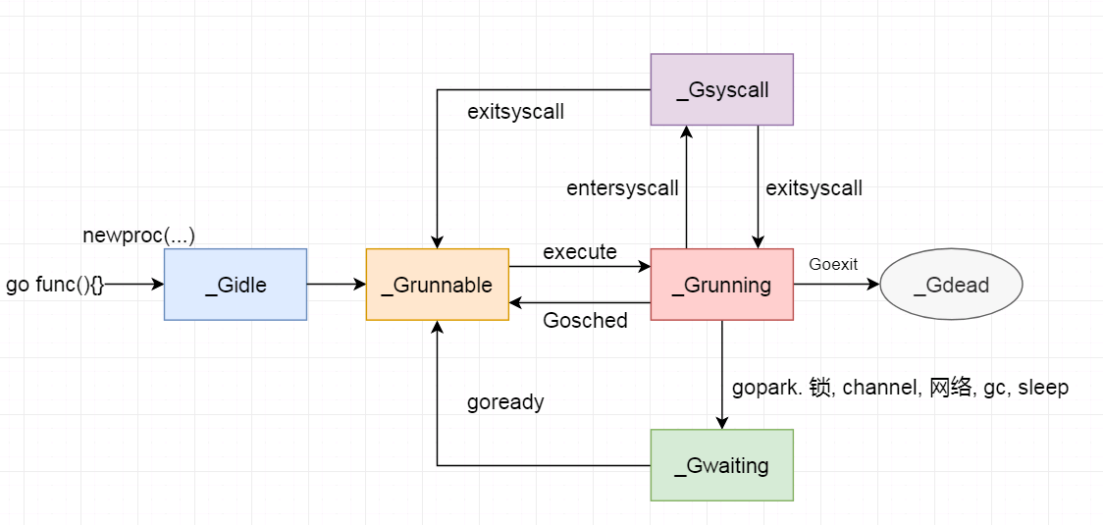
g 的 atomicstatus 存储了当前 Goroutine 的状态:
| 状态 | 值 | 说明 |
|---|---|---|
_Gidle |
0 | 刚分配, 尚未初始化 |
_Grunnable |
1 | 还没有被运行, 在runqueue上 |
_Grunning |
2 | 可能在执行, 拥有栈的所有权, 与M, P已绑定, 不在runqueue上 |
_Gsyscall |
3 | 执行系统调用, 没执行代码, 只与M绑定, 不在runqueue上 |
_Gwaiting |
4 | 被阻塞, 不在 runqueue 上, 但是可能在 Channel的等待队列、锁队列 上 |
_Gdead |
6 | 没有执行代码,也没有被使用,可能在被重新初始化 |
_Gcopystack |
8 | 栈正在被拷贝,没有执行代码,不在runqueue上 |
_Gpreempted |
9 | 由于抢占而被阻塞,没有执行代码,不在runqueue, 等待被唤醒 |
_Gscan |
0X1000 | GC 正在扫描栈空间, 没有执行代码, 可与其他状态同时存在 |
状态机:
M
M 代表了操作系统线程。调度器可以最多创建 10000 个线程, 但是其中大多数线程都不会执行代码(可能会陷入系统调用), 最多只会有 GOMAXPROCS 个活跃的线程能够正常运行。
默认情况下 GOMAXPROCS 会被设置成当前机器的核心数。而调度器也会启动 CPU 个数的 runtime.m, 最大化利用机器性能, 尽可能不让机器启动过多的线程而浪费了线程切换消耗的性能
(Goroutine 切换 比 线程切换 消耗性能低)。
接下来我们也来看看 runtime.m 的数据结构
type m struct {
g0 *g // m 持有的 Goroutine 用于执行调度指令
...
procid uint64 // 底层线程id (PID)
gsignal *g // 处理 signal 的 Goroutine
...
tls [6]uintptr // 本地线程存储 (传给 FS寄存器的线程局部存储)
mstartfn func() // m 启动时的函数
curg *g // 当前正在运行( 执行代码 ) 的 Goroutine
...
p puintptr // m 执行代码时持有的 p (没有执行代码时为 nil )
nextp puintptr // 暂存的 p
oldp puintptr // 执行系统调用之前使用 执行程序的 p
id int64 // id
spinning bool // m 没有可以执行的 g, 正在寻找可以执行的 g (自旋 spin); 其实 m 就两个状态 自旋(spinning) 和 运行(runing)
...
incgo bool // m 正在执行 CGO 调用
...
mcache *mcache // 运行代码是 绑定的 p 的 mache
...
}
g0 是一个运行时比较特殊的 Goroutine, 它会深度参与运行时的调度过程,包括 Goroutine 的创建,大内存的分配,CGO 函数的执行。
除了上面列出的字段, m 还存在着大量与线程状态,锁,调度,系统调用相关的字段。之后我们再具体介绍
m 也存在状态机, 相比 G P 要简单的多, 因为它就两种状态:

P
处理器 这个概念在 Go 最早的若干版本并没有被引入(最早 1.1版本引入)。 它是 m 与 g 的中间层,提供 m 需要的上下文环境, 也会负责调度 g 等待队列, 使得每个 内核线程都能够充分利用。 可以在 Goroutine 进行 I/O 操作时及时切换,提高线程的利用率。
调度器在启动时,就会创建 GOMAXPROCS 个p,这些处理 会绑定到不同的 m 上 ,充分利用机器性能。
下面我们也来看看 p 的字段
type p struct {
id int32 // p id
status uint32 // p 的状态; _Pidle, _Prunning...
...
m muintptr // 反向链接到关联的 m (nil 则表示 idle)
mcache *mcache // pre-p的分配cache
pcache pageCache // 页面缓存
...
deferpool [5][]*_defer // 不同大小的可用的 defer 结构池
deferpoolbuf [5][32]*_defer
runqhead uint32 // p 的运行队列头
runqtail uint32 // p 的运行队列尾
runq [256]guintptr// p 的运行队列
runnext guintptr // 下一个需要执行的 Goroutine
gFree struct {
gList
n int32
}
...
palloc persistentAlloc // per-P to avoid mutex
gcw gcWork
...
}
除了我们列出的, runtime.p 还包含性能追踪,垃圾回收,计时器相关的字段。
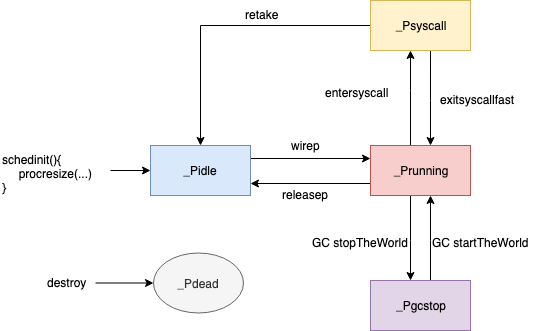
其 status 存储了 p 的状态:
| 状态 | 值 | 说明 |
|---|---|---|
_Pidle |
0 | 没有运行用户代码或调度程序,被空闲队列或者改变其结构的结构持有,runqueue为空 |
_Prunning |
1 | 被 M 持有, 正在执行用户代码或调度程序 |
_Psyscall |
2 | 没有执行用户代码,正在陷入系统调用 |
_Pgcstop |
3 | 被 M 持有, 当前 p 由于垃圾回收被停止 |
_Pdead |
4 | 当前处理器已经不被使用 |
P 状态机:
至此, 我们已经大致的了解了 Scheduler 中 MPG 的大致构成。接下来我们就分析分析 Scheduler 究竟是怎么运行的。
Scheduler 启动
Scheduler 初始化, 我们逐一分析它的过程:
func schedinit() {
_g_ := getg() // 获取当前 Goroutine
if raceenabled { ... } // const raceenabled = false
sched.maxmcount = 10000 // 设置最大线程数 10000; Go 语言启动最大线程数为 10000
tracebackinit() // traceback 初始化
moduledataverify() // moduleData 验证
stackinit() // 堆栈初始化
mallocinit() // 内存分配初始化
fastrandinit() // 随机数模块初始化
mcommoninit(_g_.m) // M 初始化
cpuinit() // 初始化 cpu 相关的配置信息
alginit() // algebra(代数模块)初始化
modulesinit() // 初始化活跃的 模块
typelinksinit() // 初始化类型链接
itabsinit() // 初始化 itabs
msigsave(_g_.m) // 将信号遮码保存到 主线程 m
initSigmask = _g_.m.sigmask // 初始化信号遮罩
goargs() // 获得运行传参
goenvs() // 获得环境信息
parsedebugvars() // 解析调试变量
gcinit() // gc 初始化
sched.lastpoll = uint64(nanotime()) // 初始化上次网络轮训时间
procs := ncpu // P 数量设置成 cpu 数量
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 { // 如果有全局设置,则 P 数量设置为 GOMAXPROCS
procs = n
}
if procresize(procs) != nil { // 调整 P 的数量( P 初始化 )
throw("unknown runnable goroutine during bootstrap")
}
...
}
可以看到 schedinit 主要完成了程序变量的初始化,和一些 OS 相关模块的初始化, 其中定义了 Go 的最大线程数, P的默认个数等变量,
同时, M 的初始化 和 P 的初始化 是我们这里关注的重点。
M 初始化
在 Scheduler 初始化中,初始化 M 的 函数是 runtime.mcommoninit(), 下面我们来看看这个函数的执行过程:
func mcommoninit(mp *m) {
_g_ := getg() // 获得当前 Goroutine
if _g_ != _g_.m.g0 {
callers(1, mp.createstack[:]) // 如果 当前线程不是 M 的 g0, 创建堆栈
}
lock(&sched.lock) // 上锁
if sched.mnext+1 < sched.mnext { // 守卫: 判断 线程数是否溢出
throw("runtime: thread ID overflow")
}
mp.id = sched.mnext // 给 m 设置 id (实际上是当前 m 的创建序列)
sched.mnext++ // mnext ++
checkmcount() // 守卫: 判断 m 数量是否超过 限制(默认10000)
// 初始化 m 随机数
mp.fastrand[0] = uint32(int64Hash(uint64(mp.id), fastrandseed))
mp.fastrand[1] = uint32(int64Hash(uint64(cputicks()), ^fastrandseed))
if mp.fastrand[0]|mp.fastrand[1] == 0 {
mp.fastrand[1] = 1
}
mpreinit(mp) // 为 m 初始化一个 专门处理信号的 g
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + _StackGuard
}
// 添加到 allm 中,从而当它刚保存到寄存器或本地线程存储时候 GC 不会释放 g.m
// 这里 allm 指向最后一个 m ,它用于将新的 m 的 allink 引导指向 上一个 m, 在将 allm 指向最新的 m; 这样所有的 m 就链接起来了
mp.alllink = allm
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock) // 解锁
if iscgo || GOOS == "solaris" || GOOS == "illumos" || GOOS == "windows" { // 若 GC 奔溃, 分配内存保存 TraceBack
mp.cgoCallers = new(cgoCallers)
}
读完mcommoninit发现它只是对 m 进行了一个初步的初始化: 1.设置id; 2.创建 signal 处理 g ; 3. 链接到 allm; 尚未涉及到 线程处理工作。
P 初始化
在 schedinit中 P 的初始化 使用了 runtime.procresize 这个函数的本来用途是 调整 P 的数量。但在这里我们用作初始化 P 的个数:
func procresize(nprocs int32) *p {
old := gomaxprocs // 获得Go启动后 P 的最大数量数量
if old < 0 || nprocs <= 0 { // 守卫: 判断 p 数量是否异常
throw("procresize: invalid arg")
}
if trace.enabled { // 记录Trace事件
traceGomaxprocs(nprocs)
}
now := nanotime() // 获取当前系统时间
if sched.procresizetime != 0 { // 记录 p 总用时: (当前时间 - 上次更改 p 的时间) * p 数量 + 上次记录的总用时
sched.totaltime += int64(old) * (now - sched.procresizetime)
}
sched.procresizetime = now // 记录最后一次更改 p 数量的时间
// 该函数的主要部分 :更新 p 的数量
if nprocs > int32(len(allp)) { // 若预期 p 的数量大于当前运行的 p 的数量 (allp 是个切片)
lock(&allpLock) // 上锁
if nprocs <= int32(cap(allp)) { // 若预期 p 的数量 小于 allp 的容量(这里 allp 的容量大小是 程序执行至今 p 最多的时刻的 p 数量)
allp = allp[:nprocs] // 直接取切片(没有释放 多余 p 的空间)
} else { // 若 历史最大 P 数量 小于 预期 P 数量 :
nallp := make([]*p, nprocs) // 按照预期 P 的数量创建空间
copy(nallp, allp[:cap(allp)]) // 将 allp 直接复制到 新创空间中 (ps: 旧 P 已经初始化过)
allp = nallp // allp 指针指向 新创建的空间
}
unlock(&allpLock) // 解锁
}
// 遍历初始化需要新创建的 P
for i := old; i < nprocs; i++ { // 循环 需要创建的 P 的次数( 历史最大 P 数量 ~ 预期数量)
pp := allp[i]
if pp == nil { // 若 当前位置 nil,开辟空间创建 P 对象 (理论上应该都是 nil)
pp = new(p)
}
pp.init(i) // 初始化新创建的 p, (使用序列 i 作为 p 的 ID)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp)) // &allp[i] 指向 pp
}
// 调整 p 的工作状态
_g_ := getg() // 获取当前 Goroutine
if _g_.m.p != 0 && _g_.m.p.ptr().id < nprocs {
// 若执行当前 G 的 M( 也可以说 线程; 个人还是倾向于 M 是 线程的指代/抽象) 存在 (m.p 是个 uintptr 默认值为 0),
// 且其ID小于预期 P 的数量, 则继续使用当前的 P
_g_.m.p.ptr().status = _Prunning // 更改 当前 P 状态 为 Running
_g_.m.p.ptr().mcache.prepareForSweep() // 清空页面缓存
} else { // 当前 M 不存在 P 或者 P 的 id 已经大于当前 P 规定数量
if _g_.m.p != 0 { // 当前 M 的 P 存在( 且序列已经超过预期 P 的个数 )
if trace.enabled { // Trace 记录 并 停止 P 执行
traceGoSched()
traceProcStop(_g_.m.p.ptr())
}
_g_.m.p.ptr().m = 0 // 清楚 预释放 P 的 m指针 (不能让 停止的 p 还携带 m)
}
// M 的 P 不存在( 或者刚刚被清楚了 )
_g_.m.p = 0 // 清空 当前 m 的 P 指针
_g_.m.mcache = nil // 清空当前 M 的 mcache (这个 mcache 实际上是从 P 中取到的)
p := allp[0] // 将 id = 0 的 p 交给 当前 M
p.m = 0 // 释放 这个 P 的 M 指针 ( id 为 0 的 P 不再为别的 M 服务了)
p.status = _Pidle // 重置 P 状态
acquirep(p) // 关联当前 P 和 M
if trace.enabled {
traceGoStart() // 记录 Trace 事件
}
}
for i := nprocs; i < old; i++ { // 遍历多余的 P
p := allp[i]
p.destroy() // 释放 P 的资源, 并将其转为 PDead
}
}
到此我们可以观察到 这个函数的主要工作 就是 调整 P 的数量, 在我们初始化 Scheduler 中用作: 保持 P 的数量为机器核心数。
而具体的 P 是如果 初始化的,procresize 调用了 runtime.p.init
func (pp *p) init(id int32) {
pp.id = id // 赋予 id
pp.status = _Pgcstop // 初始化 status
pp.sudogcache = pp.sudogbuf[:0] // 初始化 sudog 队列的 cache
for i := range pp.deferpool { // 初始化 defer 池
pp.deferpool[i] = pp.deferpoolbuf[i][:0]
}
pp.wbBuf.reset()
// 分配 cache
if pp.mcache == nil { // 若当前 p 没有 cache空间
if id == 0 { // 且是第一个创建的
if getg().m.mcache == nil { // 守卫: 验证当前 M 的 cache 不为空
throw("missing mcache?")
}
pp.mcache = getg().m.mcache // 当前(最早创建的) M 的 cache (引导空间) 交给 最早创建的 P
} else {
pp.mcache = allocmcache() // 分配新空间
}
}
if raceenabled && pp.raceprocctx == 0 { ... } // const raceenabled = false
}
runtime.p.init 主要是为 P 分配了各类的空间
G 初始化
我们并没有在 runtime.schedinit 中找到 G 初始化的蛛丝马迹, 实际上在我们代码中使用的 go 关键字, 会被 Go 编译器转换成 runtime.newproc
func newproc(siz int32, fn *funcval) { // siz 是参数长度, fn 是 go 执行的函数的引用指针
argp := add(unsafe.Pointer(&fn), sys.PtrSize) // 从 fn 的地址增加一个指针的长度,从而获取第一个参数的地址
gp := getg() // 获得当前 G
pc := getcallerpc() // 获得 pc 寄存器
systemstack(func() { // 使用系统堆栈调用下面的函数
newproc1(fn, argp, siz, gp, pc) // 创建 G
})
}
简单对传参进行加工,然后调用 runtime.newproc1
func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) {
_g_ := getg() // 获得当前 G
if fn == nil { // 守卫: 判断 fn 是否是 nil
_g_.m.throwing = -1
throw("go of nil func value")
}
acquirem() // _g_ := getg(); _g_.m.locks++; 禁止当前 m 被抢占因为它可以在一个局部变量中保存 p
siz := narg
siz = (siz + 7) &^ 7 // 8字节对齐。
if siz >= _StackMin-4*sys.RegSize-sys.RegSize { // 守卫: 穿参过大,超过内存控制范围
throw("newproc: function arguments too large for new goroutine")
}
_p_ := _g_.m.p.ptr // 当前 P
newg := gfget(_p_) // 通过 P 获得一个新 G
if newg == nil { // 如果 新 G 是空的
newg = malg(_StackMin) // 创建一个拥有 _StackMin 大小的栈的 g
casgstatus(newg, _Gidle, _Gdead) // 将新创建的 g 从 _Gidle 更新为 _Gdead 状态
allgadd(newg) // 将 Gdead 状态的 g 添加到 allg,这样 GC 不会扫描未初始化的栈
}
if newg.stack.hi == 0 { // 守卫: 判断 newg 拥有的栈大小是否没有初始化
throw("newproc1: newg missing stack")
}
if readgstatus(newg) != _Gdead { // 守卫: 判断 newg 的状态 是否是 _Gdead
throw("newproc1: new g is not Gdead")
}
// 计算运行空间大小,对齐
totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // 计算程序需要的运行空间
totalSize += -totalSize & (sys.SpAlign - 1) // 对齐到 spAlign
sp := newg.stack.hi - totalSize // 确定 sp 入栈位置
spArg := sp // 确定 参数 入栈位置
if usesLR {
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
if narg > 0 { // 存在传参
memmove(unsafe.Pointer(spArg), argp, uintptr(narg)) // 将传参的内容,复制到 新 G 的执行栈
if writeBarrier.needed && !_g_.m.curg.gcscandone { // 如果当前写屏蔽开启, 并且当前 G 的堆栈尚未被 GC 扫描
f := findfunc(fn.fn) // 通过原方法的指针(开辟新的空间)构建方法对象(funcInfo)
stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps)) // 将新创建的方法对象指针封装成栈映射对象(stackmap)
if stkmap.nbit > 0 { // 若栈映射对象的索引大于 0
bv := stackmapdata(stkmap, 0) // 获取堆栈第0位的位向量
bulkBarrierBitmap(spArg, spArg, uintptr(bv.n)*sys.PtrSize, 0, bv.bytedata) // 重新将参数复制到 G 的执行栈
}
}
}
// 清理、创建并初始化的 g 的运行现场
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched)) // 清空 新创建的 G 的运行现场
newg.sched.sp = sp // 初始化 运行现场的 sp 偏移量
newg.stktopsp = sp // 初始化 sp 堆顶偏移量
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // 初始化 pc 偏移量
newg.sched.g = guintptr(unsafe.Pointer(newg)) // 初始化 调度信息的 g (newg 获取指针 给 sched.g)
gostartcallfn(&newg.sched, fn) // 根据 fn, 系统信息 调整 sched 的 sp, pc, ctxt
// 初始化 newg 的状态
newg.gopc = callerpc // 新 G 继承 当前 G 的 pc
newg.ancestors = saveAncestors(callergp) // 当前 G 封装成 []ancestorsInfo 赋值给 ancestors (祖先 g 列表)
newg.startpc = fn.fn // 当前 G 的初始 PC 指向 fn的地址
if _g_.m.curg != nil { // 若当前 M 运行的 G 不为空:
newg.labels = _g_.m.curg.labels // 新 G 继承 当前 M 运行的 G 的 标签
}
if isSystemGoroutine(newg, false) { // 若 新创建的 g 是 System Goroutine 运行现场的系统g统计 + 1
atomic.Xadd(&sched.ngsys, +1)
}
casgstatus(newg, _Gdead, _Grunnable) // 完成 newg 初始化, 转为 _Grunable 状态
// 分配 goid
if _p_.goidcache == _p_.goidcacheend {
_p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)
_p_.goidcache -= _GoidCacheBatch - 1
_p_.goidcacheend = _p_.goidcache + _GoidCacheBatch
}
newg.goid = int64(_p_.goidcache)
_p_.goidcache++
if raceenabled { ... } // const raceenabled = false
if trace.enabled { // 记录 Trace 事件
traceGoCreate(newg, newg.startpc)
}
runqput(_p_, newg, true) // 将这里新创建的 g 放入 p 的本地队列或直接放入全局队列
// 如果有空闲的 P、且 spinning 的 M 数量为 0,且主 goroutine 已经开始运行,则进行唤醒 p
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && mainStarted {
wakep()
}
releasem(_g_.m) // 为 M 解锁 (回应 函数开头防止 M 被抢占上锁)
}
newproc1 这个函数十分复杂, 大概步骤总结下来:
- 获得一个
_Gdead状态的 g:- 首先尝试从 P 本地 gfree 链表或全局 gfree 队列获取已经没有用的(
_Gdeaad状态的) g (gfget(_p_)) - 初始化过程中程序无论是本地队列还是全局队列都不可能获取到 g,因此创建一个新的 g,并为其分配运行线程(执行栈),这时 g 处于 _Gidle 状态
- 首先尝试从 P 本地 gfree 链表或全局 gfree 队列获取已经没有用的(
- 创建完成后,g 被更改为 _Gdead 状态,并根据要执行函数的入口地址和参数,初始化执行栈的 SP 和参数的入栈位置,并将需要的参数拷贝一份存入执行栈中
- 根据 SP、参数,在 g.sched 中保存 SP 和 PC 指针来初始化 g 的运行现场
- 将调用方、要执行的函数的入口 PC 进行保存,并将 g 的状态更改为 _Grunnable
- 给 goroutine 分配 id,并将其放入 P 本地队列的队头或全局队列(初始化阶段队列肯定不是满的,因此不可能放入全局队列)
- 检查空闲的 P,将其唤醒,准备执行 G,但我们目前处于初始化阶段,主 goroutine 尚未开始执行,因此这里不会唤醒 P。