一直以来都是以 Python 作为服务端生产语言, 但是随着业务的发展, 越来越感到 Python 的力不从心; Go 的性能很强, 语言为并发而生, 编译速度很快, 拥有众多优秀的作品(docker、kubernetes、etcd 等), 同时越来越被国内厂商青睐( 字节跳动, 拼多多, 阿里云, 京东, 知乎 等), 于是打算今后用 Go 代替 Python 作为生产工具 (当然我更看好 Rust , 但是感觉它在未来五年内是发展不起来了)
draveness 的《Go 语言设计与实现》从源码与编译后的机器码等角度深入讲述了 Go 的原理与实现, 这里将依托此文对 Go 进行更深入的学习。
正如原文作者所说:
刚刚接触 Go 语言时是有些排斥和拒绝的,一度认为 Go 语言 GOPATH 的设计非常诡异,而简单的语法也导致了低下的表达能力并且影响开发效率。但是随着对 Go 语言的深入学习和理解,作者的这一观念也在不断改变。
到了今天,作者认为我们在工业界需要这么一门语法简单的编译型语言,它能够提供简单的抽象和概念,虽然目前 Go 语言也有很多问题,但是语言以及周边工具的不断完善也让作者感受到了社区的活力,也坚定地认为这门语言未来的发展会越来愈好。
在最开始学习使用 Go 的一个月内,我也是各种不习惯,不习惯 Go 的语法,组合式的继承模式,隐性的接口表达,各种基础变量的默认值,语言的操控性太差 等等, 但是经过几个月的不断摸索、学习, 也逐渐熟悉了,Go 作者所表达的意图, 同时也认为 Go 简单的语法在工业生产中 统一员工的代码可读,有着明显的优势。
Go 编译过程
Go 是一门 编译型语言 (在代码运行之前需要编译成为二进制机器码), Go 语言编译器源码在 src/cmd/compile 目录中, ...
该部分已经迁移至新文章中
基础知识
数据结构
数组
数组和切片是 Go 语言中常见的数据结构,很多刚刚使用 Go 的开发者往往会混淆这两个概念,数组作为最常见的集合在编程语言中是非常重要的,除了数组之外,Go 语言引入了另一个概念 — 切片,切片与数组有一些类似,但是它们的不同之处导致使用上会产生巨大的差别。
Go 语言中的数组在初始化之后大小就无法改变, 存储元素类型与数组大小共同决定了数组的类型
初始化
arr1 := [3]int{1, 2, 3} // 上限推导
arr2 := [...]{1, 2, 3} // 语句转化
两种声明方式在运行期间得到的结果完全相同, 语句转化在编译期间会被转化为第一种形式,
访问与赋值
数组在内存中其实就是一连串内存空间, 表示数组的方式就是一个指向数组开头的指针, 如果不知道数组大小, 就有可能发生越界, 不过不知道元素类型, 就不知道一次取出多少字节数据, 数组访问越界在编译期间就会被检测出.
切片
数组在 Go 语言中没有切片常用, 切片是动态数组, 我们可以向其中追加元素, 声明时只需要知道切片中的元素类型
[]int
[]interface{}
数据结构
编译期间的切片是Slice类型的, 但是在运行时切片由SliceHeader结构体表示, 其中Data字段指向数组的指针, Len表示当前切片的容量, 也就是Data的数组大啊小:
type SliceHeader struct{
Data uintptr // 指向数组的指针, 因为数组不允许扩充,所以 Slice 扩充时需要新开辟一个数组的空间
Len int
Cap int // 总容量
}
访问元素
len(arr), cap(arr)一般情况下会直接被替换成切片的Len 和 Cap, 获取切片中的元素 也会替换成相应的地址直接访问
追加和扩容
向切片中追加元素, 会根据元素是否会覆盖原变量, 分别进入两种流程, 如果 append 返回的新切片,则会 对结构体解构, 获取数组指针, 大小, 容量, [扩容] 并依次追加新的元素到切片.
如果 append 赋值给原切片, 则会将新切片赋值给原来的切片, 但是赋值切片根据剩余容量做了相应的优化

当容量不够时, growslice 会对切片进行扩容, 扩容就是为切片分配一块新的内存空间并将原切片的元素全部拷贝过去.
在分配内存空间之前需要先确定新的切片容量,Go 语言根据切片的当前容量选择不同的策略进行扩容:
1. 如果期望容量大于当前容量的两倍就会使用期望容量;
2. 如果当前切片容量小于 1024 就会将容量翻倍;
3. 如果当前切片容量大于 1024 就会每次增加 25% 的容量,直到新容量大于期望容量;
即便 Go 对扩容有了优化,但是 如果知道数组的最小长度, 最好还是一次性定义清楚: make([]int, 0, 10)
常用操作
list := []int{1, 2, 3, 4}
list2 := []int{5, 6, 7, 8}
list := append(list, 0) // 追加
list := append([]int{0}, list) // 头插入
list := append(list, list2...) // 合并
list := append(list[:4], list[5:]...) // 删除
list := append(list[:4], append([]int{0}, list[:4]...)...) // 插入
拷贝切片
若在编译期间 copy 会直接调用 memmove 进行 copy
若在执行阶段调用 copy, 则会使用 runtime.slicecopy 来执行
哈希表
哈希表是除了数组之外最常见的数据结构, 甚至还被用于代替 Set ( Go 语言没有直接实现 Set 结构体, 在LeeCode解题中大批量的被用于去重中)
数据结构
Go 语言运行时同时使用了多个数据结构组合表示哈希表, 其中使用hmap结构体来表示哈希:
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}
count 表示当前哈希表中的元素数量; B 表示 buckets的数量(但是该字段存buckets 的对数), len(buckets) == 2 ^ B; hash0 是哈希的种子,它能为哈希函数的结果引入随机性,这个值在创建哈希表时确定,并在调用哈希函数时作为参数传入; oldbuckets 是哈希在扩容时用于保存之前 buckets 的字段,它的大小是当前 buckets 的一半;
extra 是溢出桶
初始化
// 字面量
hash := map[string]int{
"1": 2,
"3": 4,
"5": 6,
}
// 运行时
hash := make(map[string]int, 3)
常用操作
for k, v := range hash { // 遍历
// k, v
}
hash[key] = value // 写入
delete(hash, key) // 删除
v := hash[key] // 读取
v, ok := hash[key] // 读取
Go 语言使用拉链法来解决哈希碰撞的问题实现了哈希表,它的访问、写入和删除等操作都在编译期间转换成了运行时的函数或者方法。
哈希在每一个桶中存储键对应哈希的前 8 位,当对哈希进行操作时,这些 tophash 就成为了一级缓存帮助哈希快速遍历桶中元素,每一个桶都只能存储 8 个键值对,一旦当前哈希的某个桶超出 8 个,新的键值对就会被存储到哈希的溢出桶中。
随着键值对数量的增加,溢出桶的数量和哈希的装载因子也会逐渐升高,超过一定范围就会触发扩容,扩容会将桶的数量翻倍,元素再分配的过程也是在调用写操作时增量进行的,不会造成性能的瞬时巨大抖动。
字符串
字符串虽然被看作一个整体, 但实际上是一片连续的内存空间
数据结构
type StringHeader struct {
Data uintptr
Len int
}
数据结构和 Slice 十分相像, 少了 Cap (不需要容量), Data 指向 连续的内存地址
语言基础
函数调用
调用实现
Go 语言和C 语言 在设计函数的调用习惯时选择了不同的实现。C 语言同时使用寄存器和栈传递参数, 使用 eax 存储器传递返回值;而 Go 语言使用栈传递参数与返回值。:
- C 语言的方式能够极大地减少函数调用的额外开销,但是增加了实现的复杂度;
- CPU 访问栈的开销比访问寄存器高几十倍;
- 需要单独处理函数过多的情况;
- Go 语言的方式降低了实现复杂度并支持多返回值,但是牺牲了函数调用的性能;
- 不需要考虑超过寄存器数量的参数应该如何传递;
- 不需要考虑不同架构上的寄存器差异;
- 函数入参和出参的内存空间需要在栈上进行分配;
Go 语言使用栈作为参数和返回值传递的方法是综合考虑后的设计,选择这种设计意味着编译器会更加简单、更容易维护。
参数传递
Go 语言在传递参数时是传值还是传引用也是一个有趣的问题,这个问题影响的是当我们在函数中对入参进行修改时会不会影响调用方看到的数据。
我们先来介绍一下传值和传引用两者的区别:
- 传值:函数调用时会对参数进行拷贝,被调用方和调用方两者持有不相关的两份数据;
- 传引用:函数调用时会传递参数的指针,被调用方和调用方两者持有相同的数据,任意一方做出的修改都会影响另一方。
不同语言会选择不同的方式传递参数,Go 语言选择了传值的方式,无论是传递基本类型、结构体还是指针,都会对传递的参数进行拷贝。 (怪不得 Go 在使用中都直接创建指针,很少直接使用结构体,如果在传递较大结构体时候会占用很多的内存与机器性能)
接口
Go的接口就是一组方法的签名, 它是Go重要的组成部分 在系统中, 可以通过面向接口编程进行上下游接口解耦,降低系统维护的难度。
人能同时处理的信息非常有限,定义良好的接口能够隔离底层实现,让我们将重点放在当前的代码片段中。
在Go中, 接口实现的所有方法都是隐式实现,
接口的类型
接口也是 Go 语言中一种类型, 它能够出现在变量的定义、函数的入参、返回值中,并对其值进行约束, 不过Go语言中有两种略微不同的接口(iface),
一种是带方法的接口,另一种是不带方法的接口的 interface{} (eface),
interface类型也是一种类型,它不像其它语言代表任意类型, 如果发生类型转化,再获取变量类型,或得到的就是 interface{}
package main
func main() {
type Test struct{}
v := Test{}
Print(v) // (0x1063640,0x10f68e8)
}
func Print(v interface{}) { // 传入的参数将会发生 隐性类型转换
println(v)
}
接口与指针
有些时候实现接口的并不是结构体,而是结构体的指针类型
type Cat struct {}
type Duck interface { ... }
func (c Cat) Quack {} // 使用结构体实现接口
func (c *Cat) Quack {} // 使用结构体指针实现接口
var d Duck = Cat{} // 使用结构体初始化变量
var d Duck = &Cat{} // 使用结构体指针初始化变量
| 结构体实现接口 | 结构体指针实现接口 | |
|---|---|---|
| 结构体初始化变量 | 通过 | 不通过 |
| 结构体指针初始化变量 | 通过 | 通过 |
为什么 结构体指针 可以通过两种实现接口的形式, 而 结构体 初始化的不行?
作为指针变量能够隐式地获取到指向的结构体,所以能在结构体上调用接口实现方法。 而反之则不行,结构体不能获取结构体指针,从而无法获取到指针的函数。
nil 和 non-nil
package main
type TestStruct struct{}
func NilOrNot(v interface{}) bool {
return v == nil
}
func main() {
var s *TestStruct
fmt.Println(s == nil) // #=> true
fmt.Println(NilOrNot(s)) // #=> false
}
调用函数时发生了隐式类型转换, *TestStruct 类型会转换成 interface{} 类型,
转换后的变量不仅包含转换前的变量,还包含了变量的类型信息 TestStruct, 所以转换后的变量与 nil 不相等
type eface struct { // 16 bytes
_type *_type
data unsafe.Pointer
}
interface{} 的数据结构中 包含了原有数据结构的类型信息(_type),所以新创建的对象的属性并不是初始化类型,即不为 nil
类型转换 TODO
接口在运行时也是一种特殊的类型,那么在使用中就难免进行一些类型转化
我们经常使用一种在函数调用过程中产生的隐形类型转换:
type str interfcae{}
func main(){
a := "hello"
print(a)
}
func print(v str){
fmt.Println(v.(type))
}
反射
反射是 Go 比较重要的特性, 虽然在大多数应用和服务中不常见, 但是很多框架都依赖反射机制简化代码逻辑。 因为 Go 语法元素很少, 设计简单, 所以没有特别强的表达能力, 但是 Go 的reflect包能弥补 Go 在语法上的一些劣势。
reflect实现了运行时的反射能力, 可以让程序操作不同类型的对象。反射包中有两对非常重要的函数:reflect.TypeOf 和 Type 与 reflect.ValueOf 和 Value
反射函数和类型
Type与reflect.TypeOf
Type是反射包定义的一个接口, 我们可以用reflect.TypeOf函数获取任意变量的类型,
type Type interface {
Align() int
FieldAlign() int
Method(int) Method // 返回第i个方法
MethodByName(string) (Method, bool) // 可以获得当前累心对应方法的引用
NumMethod() int
...
Implements(u Type) bool // 可以判断当前类型是否实现了某个接口
...
}
Value 与 reflect.ValueOf
Value的类型与Type不同,他被声明成了结构体。这个结构体对外没有暴露的字段,但是提供了一系列获取或写入的方法。
type Value struct {
// contains filtered or unexported fields
}
func (v Value) Addr() Value // 获取v的地址指针, (如果v的底层值是unaddressable类型则会panic)
func (v Value) Bool() bool // 获取v的bool值,(如果v的底层值不是bool类型则会panic)
func (v Value) Bytes() []byte // 获取vbytes底层值,(如果v的底层值不是字节片段,则会panic)
...
反射包中的所有方法都基本围绕着 Type 和 Value 这两个类型设计的.我们可以通过 reflect.TypeOf 、 reflect.ValueOf 可以将一个普通的变量转换成 Type 或
Value, 然后利用 反射包中的方法对他们进行复杂的操作。
三大法则
运行时反射是程序在运行期间检查自身结构的一种方式. 反射带来的灵活性是一把双刃剑, 反射作为一种元编程方式可以减少重复代码, 但是过量的使用反射会使得程序变得难以理解且缓慢. 三大法则包括:
- 从interface{}变量可以反射出反射对象; // 如果传入参数不是
interface{},则会发生隐式类型转换 - 从反射对象可以获取interface{}变量; //
reflect.Value.Interface方法可以从反射对象(Value)获得interface{}对象 , 然后我们可以通过类型转换获得其他类型或接口。 - 要修改反射对象, 其值必须可以设置; // 如果
Value的底层类型,不可更变, 则会panic
第三点的一个例子:
func main() {
i := 1
v := reflect.ValueOf(i)
v.SetInt(10)
fmt.Println(i)
}
panic: reflect: reflect.flag.mustBeAssignable using unaddressable value
int 类型不是指针类型 无法发生更改, 所以这段函数需要这样写, 获取 i 变量的指针对象进行操作:
func main() {
i := 1
v := reflect.ValueOf(&i)
v.Elem().SetInt(10)
fmt.Println(i)
}
$ go run reflect.go
10
Go 语言的 reflect 包为我们提供的多种能力,包括如何使用反射来动态修改变量、判断类型是否实现了某些接口以及动态调用方法等功能,通过对反射包中方法原理的分析能帮助我们理解之前看起来比较怪异、令人困惑的现象。
常用关键字
for 和 range
循环是所有编程语言都有的控制结构,除了经典的 "三段式" (for i:=1; i<10; i++) 循环外, Go 还引入了一个关键字 range ( Python 选手感觉很熟悉) ,
它可以帮助我们快速遍历数组、切片、哈希表、以及 Channel 等集合类型。
原文在讲述这一节时,分别从 语法树、编译后的汇编代码 角度分析了 Go 在实现 for/for range 的过程与产生的问题。详细请见原文,
我们直接从一些表象入手进行学习:
现象
由于 Go 的特殊实现形式,我们在使用 for 和 range 会遇到一些 "令人不可思议的" 现象,循环永动机
func main() {
arr := []int{1, 2, 3}
for _, v := range arr {
arr = append(arr, v)
}
fmt.Println(arr)
}
$ go run main.go
1 2 3 1 2 3
// 对于所有的 range 循环,Go 语言在编译器期间会转换成经典的三段式 for 循环, 而 循环的起始与终止的索引循环开始之前就已经被确定了。
数组循环内修改
func main() {
a := [...]int{1, 2, 3}
for i, v := range a {
if i == 0 {
a[1] = 10
}
fmt.Printf("%d: %d - %d \n", i, a[i], v)
}
}
$ go run main.go
0: 1 - 1
1: 10 - 2
2: 3 - 3
// 对于所有的 range 循环,Go 会复制出一份循环体ha,用于遍历, 而这里的 v 指向的便是ha中的一个元素
// 不过需要主要,这个例子中循环体是数组
神奇的指针
这个例子是在使用Go中经常会犯的错误。
func main() {
arr := []int{1, 2, 3}
newArr := []*int{}
for _, v := range arr {
newArr = append(newArr, &v)
}
for _, v := range newArr {
fmt.Println(*v)
}
}
$ go run main.go
3 3 3
// 对于 for _, v := range xxx 中,
// 每个循环体的值都会被赋值于同一个新变量 v (所以 循环中v拥有同样的地址空间),
// 正确的做法应该是使用 &arr[i] 替代 &v
遍历清空数组
当我们想在Go语言中清空一个切片或哈希表时,一般情况下都会认为遍历清空是非常消耗性能的事情, 但是Go对清空实行了优化, 会直接使用runtime.memclrNoHeapPointers 清空切片中的数据。
func main() {
arr := []int{1, 2, 3}
for i, _ := range arr {
arr[i] = 0
}
}
Map随机遍历
func main() {
a := map[int]int{
1: 1,
2: 2,
3: 3,
}
for k, v := range a{
fmt.Print(k, v, "|")
}
fmt.Println()
for k, v := range a{
fmt.Print(k, v, "|")
}
}
$ go run main.go
2 2|3 3|1 1|
1 1|2 2|3 3|
// Go 在使用 for range 遍历map时 会获得随机的key顺序
// 这是 Go 语言故意的设计, 为了让使用者不依赖与go的顺序
经典循环 与 for range 循环
经典循环在编译器看来是一个OFOR类型的节点, 它有四个部分组成:
- 初始化循环的 Ninit;
- 循环的继续条件 Left;
- 循环体结束后执行的 Right;
- 循环体 NBody;
for Ninit; Left; Right{
NBody
}
而for range 相对经典循环更加复杂,这种循环会在编译期间被编译器转换为 OFOR 经典循环,之后与经典循环编译一致 被编译为 SSA
ORANGE -> OFOR -> SSA
所以对于 Go 而言, 代码在编译后 for / for range 区别并不大
遍历数组与切片
-
cmd/compile/internal/gc.arrayClear是一个非常有趣的优化,这个函数会优化 Go 语言遍历数组或者切片并删除全部元素的逻辑: 相比于依次清除数组或者切片中的数据,Go 语言会直接使用runtime.memclrNoHeapPointers或者runtime.memclrHasPointers函数直接清除目标数组对应内存空间中的数据,并在执行完成后更新用于遍历数组的索引 从而提高了遍历置零的效率(现象:遍历清空数组) -
我们使用
for range会被编辑器翻译成三段式的 for 循环, 而循环的 起始位置,终止条件,在循环开始前就会被确定(现象:循环永动机) - 当使用 for range 时, 程序不会直接使用被遍历的对象,Go会额外创建一个新的变量 ha,将原有结构体的值赋给 ha,而我们所遍历的其实是 ha。(但是 我们如果在循环体内获取遍历对象实际上还是原来的遍历对象,这点没有被转译)(现象:数组循环内修改)
- 如果使用的是 for _, v := range items 时, Go 语言会额外创建一个新的 v2 变量存储切片中的元素;在每次循环中,v2会被赋予新的值,在赋值时也发生了拷贝。(现象:神奇的指针)
for range 被编译器解析后的代码:
var v1, v2 *Node
...
ha := a // 原始的切片被赋值给 ha
hv1 := 0
hn := len(ha) // 遍历的终止条件在遍历前就被确定
v1 := hv1 // v1 是每次循环的 index 值
for ; hv1 < hn; hv1++ {
tmp := ha[hv1] // 循环实际上读取的 被拷贝出来的切片 ha
v1, v2 = hv1, tmp // 利用 v2 获取每次变量的值(v2的地址实际已经固定)
...
}
遍历哈希表
Go 解释器处理 for range 遍历 哈希表的时候 首先会将代码 利用 runtime.mapiterinit 和 runtime.mapiternext 进行重写
(cmd/compile/internal/gc.walkrange 中进行处理)
ha := a // 和遍历切片一样, 依旧会被赋值给 ha
hit := hiter(n.Type)
th := hit.Type
mapiterinit(typename(t), ha, &hit) // mapiterinit 会初始化遍历开始的元素
for ; hit.key != nil; mapiternext(&hit) { // mapiternext 则会获得下一个被遍历的元素
key := *hit.key
val := *hit.val
}
- 在
runtime.fastrand中, Go生成了一个随机数,帮助我们随机选择一个桶开始遍历, Go团队不希望我们依赖与固定顺序进行遍历, 所以引入了不确定性。 - 而在
runtime.mapiternext中, Go会依据算法进行遍历Map 并将其指针赋值与hit(有些麻烦, 其实我不是很懂 hash map的运作原理)
这里借用原作者的总结结尾:
简单总结一下哈希表遍历的顺序,首先会选出一个绿色的正常桶开始遍历,随后遍历对应的所有黄色溢出桶,最后依次按照索引顺序遍历哈希表中其他的桶,直到所有的桶都被遍历完成。
遍历字符串
遍历字符串的过程与遍历数组、切片的非常相似, 只是在遍历中获取字符串索引所对应的字节并将其转成 rune 类型
ha := s
for hv1 := 0; hv1 < len(ha); {
hv1t := hv1
hv2 := rune(ha[hv1])
if hv2 < utf8.RuneSelf { // 这里是为了判断 字节是否达到 utf8 的数位
hv1++
} else {
hv2, hv1 = decoderune(h1, hv1) // 将读取到的字节转成 rune
}
v1, v2 = hv1t, hv2
}
通道
通过 range 遍历 Channel 也是比较常见的做法。 for v := range ch 的语句便会被转换成:
ha := a
hv1, hb := <-ha
for ; hb != false; hv1, hb = <-ha {
v1 := hv1
hv1 = nil
...
}
循环会使用 <-ch 从 管道中取出待处理的值,并阻塞当前线程。如果管道已经关闭,则会为 v1 赋值, 并清除 hv1的数据,重新陷入阻塞等待新数据导入。
TODO
select
defer
panic 和 recover
make 和 new
运行时
并发编程
上下文 Context
上下文 context.Context 是用来设置截止日期、同步信号、传递请求相关值的结构体。与 Goroutine 有比较密切的关系。 Go 语言作者希望在每个需要的函数第一个参数都传递这个变量,就像 Python 中 类函数 的第一个传参是 self 一样。
context.Context 是 Go 语言标准库的接口, 它定义了四个需要实现的方法:
- Deadline: 返回 Context 被取消的时间,也是完成工作的截止时间;
- Done: 返回一个 Channel,这个 Channel 会在当前工作完成或者上下文被取消后关闭,多次调用 Done 方法返回的是同一个 Channel;
- Err: 返回 Context 结束的原因, 它只会在 Done 返回的 Channel 被关闭时才会返回非空的值;
- 如果 Context 被取消, 会返回 Canceled 错误;
- 如果 Context 超时,会返回 DeadlineExceeded 错误;
- Value: 从 Context 中获取键对应的值,该方法可以用来传递请求特定的数据;
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
context 中提供了 context.Background , context.TODO 结构体; 而 context.WithDeadline 和 context.WithValue 会返回 Context的实现形式
设计原理
Context 被设计用作于 Goroutine 间信号的同步通信。Go 服务的每一个请求都是通过 Goroutine 处理的,做任何并发操作时处理时,Go都会启动新的 Goroutine 去处理、访问外部IO 等。
我们可能会一次创建多个 Goroutine 来处理一个任务,而 Context 的作用就是在不同的 Goroutine 之间同步特定的数据,取消信号以及处理请求的截止时间。
Goroutine 被设计成树装的结构,需要执行子任务的时候 当前的 Goroutine 就会创建一条 子 Goroutine。 而如果 父 Goroutine 因为某些原因失败后, 子 Goroutine 会由于没有收到信号继续之前的工作, 但 如果我们正确的使用 Context ,就会通知 子 Goroutine 停止无用的工作以减少资源浪费。
Demo:
func main() {
ctx, channel := context.WithTimeout(context.Background(), 1000*time.Millisecond)
defer channel()
go handle(ctx)
select {
case <-time.After(3 * time.Second):
fmt.Println("main end")
}
}
func handle(ctx context.Context) {
select {
case <-ctx.Done():
fmt.Println("handle", ctx.Err())
case <-time.After(1500 * time.Millisecond):
fmt.Println("handle end")
}
time.Sleep(1 *time.Second)
fmt.Println("sleep 1 Second")
}
// $ go run main.go
handle context deadline exceeded
sleep 1 Second
main end
可以看出 Context 超时后并不会终止函数的运行,需要手动定义超时行为, 主要用途还是在 Goroutine 间传递信息为主
默认上下文
context包中中有两个直接返回结构体的方法:context.Context , context.TODO, 它们分别会返回预先初始化好的变量 background 和 todo
这两个私有变量都是通过 new(emptyCtx) 语句初始化的,它们是指向 context.emptyCtx的指针,emptyCtx 以最简单的形式实现了 Context 接口。
而这两个变量,也几乎相同。它们仅仅在使用的环境中有些区别:
- Background 是 Context 的默认值, 其他 Context 都是从它衍生出来的。
- TODO 用于还没有确定使用哪种上下文时使用。
取消信号
context.WithCancel 函数可以从 context.Context 中衍生出一个 子 Context 并返回用于取消该 Context 的 函数( CancelFunc )。 一旦我们执行
CancelFunc , 当前 Context 以及其 子Context (整个 Context 树)都会被取消。
除了 WithCancel , context 还拥有两个可以设置超时的两个 "携带超时计时器的 WithCancel": context.WithDeadline 和 context
.WithTimeout, 不过超时 Goroutine 并不会主动退出,需要我们手写退出。
TODO
传值方法
context.WithValue 函数可以从 父 Context 中创建一个 子 Context ,其类型是 context.valueCtx:
type valueCtx struct {
Context
key, val interface{}
}
func (c *valueCtx) Value(key interface{}) interface{} {
if c.key == key {
return c.val
}
return c.Context.Value(key) // 这个方法解决了使用 父 Context 携带数据的问题, 如果自己没有携带这个值, 就交给父Context 去处理。
}
但是如果衍生的 Context 过多, 越久远的 Context key-value 获得的效率会越差(与 HashMap 相比)。
Go 语言中的 context.Context 的主要作用还是在多个 Goroutine 组成的树中同步取消信号以减少对资源的消耗和占用,虽然它也有传值的功能,但是这个功能我们还是很少用到。
在真正使用传值的功能时我们也应该非常谨慎,使用 context.Context 进行传递参数请求的所有参数一种非常差的设计,比较常见的使用场景是传递请求对应用户的认证令牌以及用于进行分布式追踪的请求 ID。
同步原语与锁
Go 是原生支持高并发协程(在Go中称作 Goroutine 或许和真正意义上的协程略有不同)的语言。而并发都离不开锁这个概念,它能保证 Goroutine 在访问同一资源(内存等)时不会出现竞争等问题。
基本原语
Go 在 sync 中提供了一些用于同步的基本原语: sync.Mutex, sync.RWMutex, sync.WaitGroup, sync.Once, sync.Cond;
Mutex 互斥锁
type Mutex struct {
state int32 // 标示当前互斥锁的状态
sema uint32 // 用于控制锁状态的信号量
}
互斥锁在默认下状态为 0, int32 中不同位标示了不同的状态:
- mutexLocked : 标示互斥锁锁定状态;
- mutexWoken : 标示从正常模式被从唤醒;
- mutexStarving : 当前的互斥锁进入饥饿状态;
- waitersCount : 当前互斥锁上等待的 Goroutine 个数;
sync.Mutex 在正常模式下,锁的等待者会按照先进先出的顺序获得锁。但是刚被唤醒的Goroutine 与 新创建的 Goroutine 竞争时, 大概率会获取不到锁。
为了减少这种情况的发生,一旦 Goroutine 超过 1ms 没有获得锁, 就会将互斥锁转换为饥饿模式。防止部分 Goroutine 饿死。
而饥饿模式,互斥锁会直接交给等待队列最前面的 Goroutine。新的 Goroutine 在该状态下不能获取锁、也不能进入自旋状态,它们只会在队列末尾等待。 如果一个 Goroutine 获得了互斥锁且它在队列的末尾或者它等待的时间少于1ms,那么当前的互斥锁会被切换到正常模式。
相比饥饿模式,正常模式的互斥锁可以提供更好的性能, 饥饿模式能避免Goroutine 由于陷入等待无法获得锁而造成的高尾延时。
Demo:
var mutex sync.Mutex
var x = 0
func main() {
for i := 0; i < 10; i++ {
go xAdd()
}
time.Sleep(1 * time.Second)
}
func xAdd() {
mutex.Lock()
defer mutex.Unlock() // 如果未上锁的时候解锁会触发 Panic
x = x + 1
fmt.Println(x)
}
互斥锁的加锁过程比较复杂,它涉及自旋、信号量以及调度等概念:
- 如果互斥锁处于初始化状态,就会直接通过置位 mutexLocked 加锁;
- 如果互斥锁处于 mutexLocked 并且在普通模式下工作,就会进入自旋,执行 30 次 PAUSE 指令消耗 CPU 时间等待锁的释放;
- 如果当前 Goroutine 等待锁的时间超过了 1ms,互斥锁就会切换到饥饿模式;
- 互斥锁在正常情况下会通过 sync.runtime_SemacquireMutex 函数将尝试获取锁的 Goroutine 切换至休眠状态,等待锁的持有者唤醒当前 Goroutine;
- 如果当前 Goroutine 是互斥锁上的最后一个等待的协程或者等待的时间小于 1ms,当前 Goroutine 会将互斥锁切换回正常模式;
RWMutex
读写锁 sync.RWMutex 是细粒度的互斥锁, 它不限制资源的并发读,但是读写, 写写操作无法并发执行。
| 读 | 写 | |
|---|---|---|
| 读 | Y | N |
| 写 | Y | N |
type RWMutex struct {
w MutexA // 提供互斥锁能力
writerSem uint32 // 用于写等待读
readerSem uint32 // 用于读等待写
readerCount int32 // 存储了当前正在执行读操作的数量
readerWait int32 // 标示当写操作被阻塞时等待读操作的个数
}
RWMutex 提供了两对常用到的函数:
- sync.RWMutex.Lock 写上锁; sync.RWMutex.Unlock 写解锁
- sync.RWMutex.RLock 读上锁; sync.RWMutex.RUnlock 读解锁
读写锁提供的服务相对复杂,但它是建立在互斥锁之上的,在提供服务的时候,拥有互斥锁的基础特性。
WaitGroup
sync.WaitGroup 用于等待一组 Goroutine 的返回,比较常见的使用场景就是 批量等待 HTTP, RPC 请求 中
requests := []*Request{...}
wg := &sync.WaitGroup{}
wg.Add(len(requests)) // 增加 wg的等待个数
for _, request := range requests {
go func(r *Request) {
defer wg.Done() // 当完成后减少 wg 的等待个数
// res, err := service.call(r)
}(request)
}
wg.Wait() // 当所有的 wg 都完成之后,程序继续进行
结构体
type WaitGroup struct {
noCopy noCopy // noCopy 用于保证waitGroup 创建后不会被拷贝
state1 [3]uint32 // 保存状态与信号量
}
WaitGroup 同时暴露出来个方法 : sync.WaitGroup.Add , sync.WaitGroup.Wait, sync.WaitGroup.Done.
- sync.WaitGroup.Add 可以为计数器增加需要等待的数量
- sync.WaitGroup.Done 对计数器中需要等待的数量-1
- sync.WaitGroup.Wait 当计数器等待数量没有清零前,使得
sync.runtime_Semacquire进入睡眠状态,完成后唤醒 Goroutine
Once
Go 语言标准库 sync.Once 可以保证Go程序运行期间,某段代码只会执行一次。
func main() {
o := &sync.Once{}
for i := 0; i < 10; i++ {
o.Do(func() {
fmt.Println("only once")
})
}
}
$ go run main.go
only once
Once 也拥有一个 Mutex锁:
type Once struct {
done uint32 // 标识是否执行过
m Mutex // 用于并发执行时只执行一次
}
sync.Once.Do 是 Once 唯一的暴露方法:
- 如果传入函数已经执行过,就直接返回;
- 如果没有执行过便 1. 上锁;2. 执行函数;3. 将done 改为1; 4. 解锁
需要注意的是:
- sync.Once.Do 方法中传入的函数只会被执行一次,哪怕函数中发生了 panic;
- 两次调用 sync.Once.Do 方法传入不同的函数也只会执行第一次调用的函数;
Cond
TODO
扩展原语
TODO
计时器
Demo:
// 设定超时
func WaitChannel(conn <-chan string) bool {
timer := time.NewTimer(1 * time.Second)
select {
case <- conn:
timer.Stop()
return true
case <- timer.C: // 超时
println("WaitChannel timeout!")
return false
}
}
// 延时函数
func DelayFunction() {
timer := time.NewTimer(5 * time.Second)
select {
case <- timer.C:
log.Println("Delayed 5s, start to do something.")
}
}
实现
Go 在不同的版本对计时器的设计略有不同,这里我们只针对1.14 进行学习
type timer struct {
pp puintptr
when int64 // 当计时器被唤醒的时间;
period int64 // 两次被唤醒的间隔;
f func(interface{}, uintptr) // 每个计时器被唤醒都会调用的函数
arg interface{} // 计时器被唤醒时调用 f 传入的参数;
seq uintptr
nextwhen int64 // 计时器处于 timerModifiedXX 状态时, 用于设置 when 字段;
status uint32 // 计时器的状态;
}
所有的计时器都以最小四叉堆的形式存在处理器 runtime.p 中。通过处理器的网络轮询器和调度器触发。
当调度器进入调度循环时,快速确定是否需要就绪一个 timer。
type p struct {
...
timersLock mutex
timers []*timer
numTimers uint32
adjustTimers uint32
deletedTimers uint32
...
}
这里的 runtime.timer 只是私有的计时器运行时表示,而对暴露出来的计时器就是我们所熟悉的 time.Timer:
type Timer struct {
C <-chan Time
r runtimeTimer
}
time.Timer 必须通过 time.NewTimer, time.AfterFunc, time.After 创建。当计时器失效后,失效的时间就会被发送给持有该计时器的Channel,
订阅 Channel 的 Goroutine 会收到失效的时间。
time.Timer 也提供了几个对外接口:
- time.Timer.Stop 停止计时器
- time.Timer.Reset 重置计时器
状态机
runtime 使用状态机的方式处理全部计时器,其中包括了10种状态和7种操作。
| 状态 | 解释 |
|---|---|
| timerNoStatus | 没有设置状态 |
| timerWaiting | 等待触发 |
| timeRunning | 运行计时器函数 |
| timeDeleted | 被删除 |
| timeRemoving | 正在被删除 |
| timeRemoved | 已经被停止并被删除 |
| timeModifying | 正在被修改 |
| timerModifiedEarlier | 被修改到了更早的时间 |
| timerModifiedLater | 被修改到了更晚的时间 |
| timerMoving | 已经被修改正在被移动 |
同时计时器的状态机也拥有 7 中操作:
- runtime.addtimer : 向当前处理器增加新的计时器;
- runtime.deltimer : 将计时器标记成 timerDeleted 删除处理器中的计时器;
- runtime.modtimer : 网络轮询器会调用该函数修改计时器;
- runtime.resettimer : 修改已经失效的计时器的到期时间,将其变成活跃的计时器;
- runtime.cleantimers : 清除队列头中的计时器,能够提升程序创建和删除计时器的性能;
- runtime.adjusttimers : 调整处理器持有的计时器堆,包括移动会稍后触发的计时器、删除标记为 timerDeleted 的计时器;
- runtime.runtimer : 检查队列头中的计时器,在其准备就绪时运行该计时器
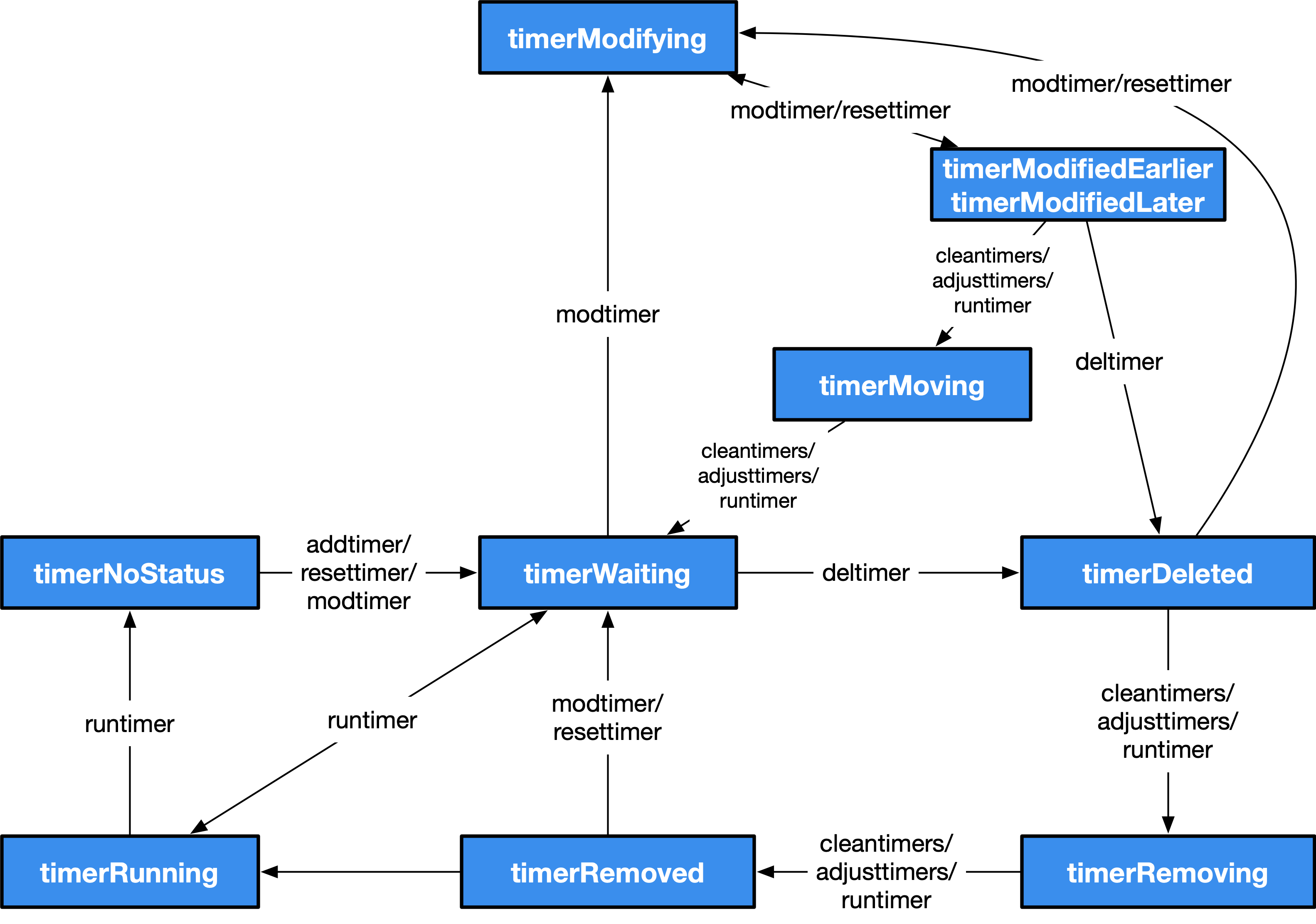
大致来看 Timer的生命周期如下:
- 一个 Timer 的标准生命周期为:NoStatus -> Waiting -> Running -> NoStatus
- 当人为的对 Timer 进行删除时:NoStatus -> Waiting -> Deleted -> Removing -> Removed
- 当人为的对 Timer 进行修改时:NoStatus -> Waiting -> Modifying -> ModifiedEarlier/ModifiedLater -> Moving -> Waiting -> Running -> NoStatus
- 当人为的对 Timer 进行重置时:NoStatus -> Waiting -> Deleted -> Removing -> Removed -> Waiting -> Running -> NoStatus
Timer 生存在 P 中,每当进入调度循环时, 都会对 Timer 进行检查,从而快速的启动那些对时间敏感的 goroutine, 这一思路也同样得益于 netpoller (网络轮训器),通过系统事件来唤醒那些对有效性极度敏感的任务。
Channel
Go 语言中 Channel 与 Select 语句受到 1978 年 CSP( Communication Sequential Process 通信顺序进程) 原始理论的启发。 在语言设计中,Goroutine 就是 CSP 理论中的并发实体, 而 Channel 则对应 CSP 中输入输出指令的消息信道, Select 语句则是 CSP 中守卫和选择指令的组合。 他们的区别在于 CSP 理论中通信是隐式的,而 Go 的通信则是显式的由程序员进行控制; CSP 理论中守卫指令只充当 Select 语句的一个分支,多个分支的 Select 语句由选择指令进行实现。
Go 语言最常见的一个设计风格就是:不要通过共享内存的形式进行通信,而是应该通过通信的方式共享内存。 虽然,使用对共享内存加互斥锁进行通信可以保证安全,但是 Go 提供了更好的通信模型, 也就是上文提到的 CSP。
先入先出
目前的 Channel 收发操作都是先入先出的形式:
- 先从 Channel 读取数据的 Goroutine 会先收到数据;
- 先向 Channel 发送数据的 Goroutine 会得到先发送数据的权利;
无锁管道
锁是一种常见的并发控制技术,我们一般会将锁分成乐观锁和悲观锁,无锁 (lock-free) 队列更准确的描述是使用乐观并发控制的队列。
Channel 在运行时的内部表示是 runtime.hchan, 该结构体包含一个用于保护成员变量的互斥锁。某种程度上,Channel 是一个用于同步和通信的有锁队列。
使用互斥锁解决程序中可能存在的线程竞争问题是很常见的。
// src/runtime/chan.go
type hchan struct {
qcount uint // 队列中的所有数据数
dataqsiz uint // 环形队列的大小
buf unsafe.Pointer // 指向大小为 dataqsiz 的数组缓冲区的指针
elemsize uint16 // 元素大小
closed uint32 // 是否关闭
elemtype *_type // 元素类型
sendx uint // Channel 的发送操作 处理到的索引 (发送索引)
recvx uint // Channel 的接受操作 处理到的索引 (接受索引)
recvq waitq // recv 等待列表,即( <-ch )
sendq waitq // send 等待列表,即( ch<- )
lock mutex
}
type waitq struct { // 等待队列 sudog 双向队列
first *sudog // sudog 是一个链式队列
last *sudog
}
其中 sendq 和 recvq 存储了 Channel 由于缓冲区空间不足而阻塞的 Goroutine 列表
其结构如下图:
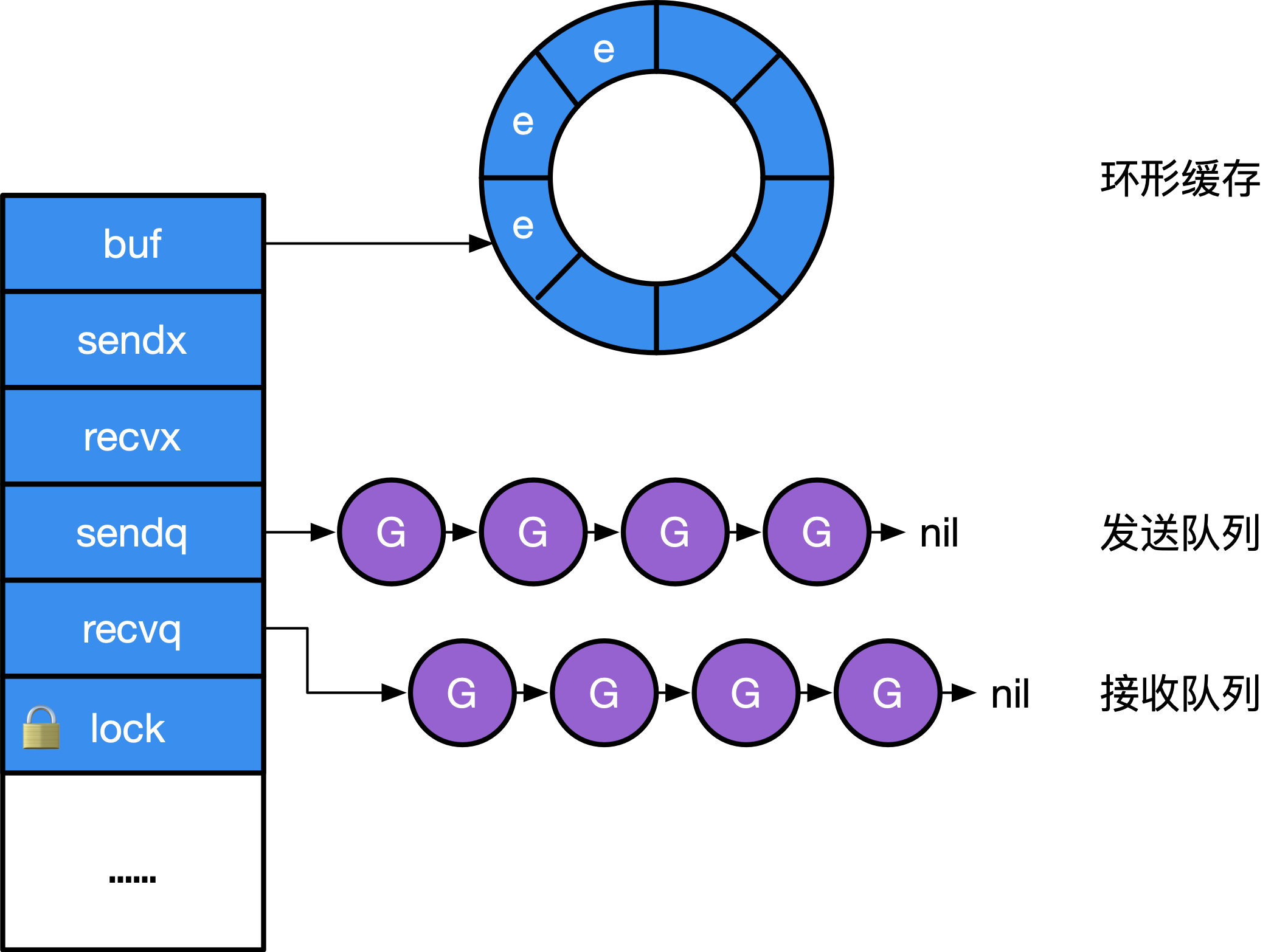
创建 Channel
Go 语言创建 Channel 会使用 make 关键字。编辑器会将 make(chan int, 10) 翻译为 makechan(int, 10) (或者 makechan64(type, 10))
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// 判断是否溢出
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
var c *hchan
switch {
case mem == 0: // 元素不具有内存空间 (int ...)
c = (*hchan)(mallocgc(hchanSize, nil, true))
c.buf = c.raceaddr()
case elem.ptrdata == 0: // 元素不包含指针
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default: // 元素包含指针
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
return c
}
Channel 创建 会根据 收发元素类型 和 元素占用缓冲区大小 来 初始化 runtime.hchan 结构体和缓冲区:
- 如果 type 类型 不存在缓冲区, 那么就只会为
runtime.hchan分配一段内存空间 - 如果 type 类型 存储的类型不是指针类型,就会为当前 Channel 和 底层数组分配一块连续的内存空间。
- 如果 type 类型 内存在指针类型,就会为
runtime.hchan分配内存,并为 type 创建 单独的内存空间。
最后根据 hchan 更新 elemsize, elemtype, dataqsiz
向 Channel 发送数据
Go 语言会使用 ch <- v 的形式发送数据,经过编译器,将会被翻译成 runtime.chansend(ch, v, true)
runtime.chansend 会经过一下几个步骤:
- 1 . 判断 ch 是否为 nil, 如果是则 使得当前 Goroutine 休眠,引发死锁崩溃
func chansend(c *hchan, ep unsafe.Pointer, block bool) bool {
// 当向 nil channel 发送数据时,会调用 gopark
// 而 gopark 会将当前的 Goroutine 休眠,从而发生死锁崩溃
if c == nil {
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan) // 使得当前 Groutine 休眠
throw("unreachable")
}
...
}
- 2 . 为 Channel 加锁,防止发生竞争。
func chansend(c *hchan, ep unsafe.Pointer, block bool) bool {
...
lock(&c.lock) // 上锁
if c.closed != 0 { // 判断 channel 是否关闭, 如果关闭则引发 panic("send on closed channel")
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
...
}
- 3 . 判断: 如果 Channel 等待队列中存在等待接受的 Goroutine 则直接发送信息 (不经过 Channel 的缓冲区, 直接发送)
func chansend(c *hchan, ep unsafe.Pointer, block bool) bool {
...
if sg := c.recvq.dequeue(); sg != nil { // 判断 recvq.dequeue() 是否为空, 即判断等待队列是否存在 Goroutine
send(c, sg, ep, func() { unlock(&c.lock) }) // 发送并解锁
return true // 结束函数
}
...
}
- 4 . 判断 Channel 的环形缓冲区是否有足够的空间
func chansend(c *hchan, ep unsafe.Pointer, block bool) bool {
...
if c.qcount < c.dataqsiz { // 判断缓存区剩余大小是否大于 type 类型的大小
qp := chanbuf(c, c.sendx) // 根据发送索引获得缓冲区的指针
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
typedmemmove(c.elemtype, qp, ep) // 将数据拷贝到缓冲区指针中
c.sendx++ // 缓冲区列表发送索引 + 1
if c.sendx == c.dataqsiz { // 若索引越界则置零
c.sendx = 0
}
c.qcount++ // 完成存入,记录增加的数据,解锁
unlock(&c.lock) // 解锁
return true // 结束函数
}
...
}
- 5 . 若 上述两种形式都不成立(即没有空间, 又没有立刻接受的 Goroutine), 则需要阻塞当前 Goroutine (
runtime.recv将唤醒它) 并 加入 ch 发送队列
gp := getg() // 获取当前 Goroutine 的指针
mysg := acquireSudog() // 分配 sudog ,
// mysg 是一个封装了 g 指针的结构体, 用于表示阻塞的 Goroutine
// 配置 当前线程的 sudog
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep // 装填 要 发送的信息
mysg.waitlink = nil
mysg.g = gp // 装填 当前 Goroutine 指针
mysg.isSelect = false // 设置 非 Select 模式 下
mysg.c = c // 将 channel 关联到 sudog
// 因为调度器在停止当前 g 的时候会记录运行现场,当恢复阻塞的发送操作时候,会从此处继续开始执行
gp.waiting = mysg // 传入需要等待的阻塞
gp.param = nil
c.sendq.enqueue(mysg) // 将 阻塞mysg 加入发送等待队列
// 将 Goroutine 陷入休眠 当唤醒后 执行 chanparkcommit
// 其实这里就是在等待 <- chan 接受信息了, 接受函数会从 channel 的 sendq 中取到 mysg 然后拿到 传递的数据
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
KeepAlive(ep) // 保证ep不被释放
if mysg != gp.waiting { // 守卫: 验证已经脱离等待, 其实很少需要验证, 接受chan消息的函数 会将其置 nil
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if gp.param == nil {
if c.closed == 0 { // 正常唤醒状态,Goroutine 应该包含需要传递的参数,但如果没有唤醒时的参数,且 channel 没有被关闭,则为虚假唤醒
throw("chansend: spurious wakeup")
}
panic(plainError("send on closed channel"))
}
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
mysg.c = nil // 取消与之前阻塞的 channel 的关联
releaseSudog(mysg) // 释放 阻塞对象
return true // 结束
可以看出 channel 发送消息主要有三种情况:
- 接受队列中有 阻塞的 Goroutine 就直接发送;
- 接受队列中无信息,如果缓存区未满,信息置入缓存区;
- 以上都不满足, 阻塞当前 Goroutine, 并将其置入发送队列;
其中 直接发送是通过 runtime.send 实现的:
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if raceenabled { // raceenable 是 const 且为 false, 所以一般一下代码不会执行。
...
}
if sg.elem != nil { // 若接受 sudog 存在指针 (指向某片空间) 可以接受数据;
// 这个判断主要过滤掉 `<- chan`
sendDirect(c.elemtype, sg, ep) // 向sg 发送 ep 数据
sg.elem = nil // sudog 对象释放指针
}
gp := sg.g // 获取 Goroutine 指针
unlockf() // 解锁 当前 channel
gp.param = unsafe.Pointer(sg) // param 是 Goroutine 唤醒 传参
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1) // 将 gp 作为下一个立即被执行的 Goroutine
}
func sendDirect(t *_type, sg *sudog, src unsafe.Pointer) {
dst := sg.elem // copy 接受指针
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size) // 写屏障 (作为原子操作) 避免内存资源竞争
memmove(dst, src, t.size) // 两块内存区域复制, 尺寸为 t.size
}
所以直接发送也是通过 runtime.sudog 作为接受载体, 其意义是等待状态下的 Goroutine,直接将数据写入 接受的指针指向的内存空间,
没有发生资源竞争,也没有浪费 channel 缓冲区。
从 Channel 接受数据
与发送消息一样, 接受消息也会被编辑器翻译成函数的形式:
v <- ch=>chanrecv(c, v, true)v, ok <- ch=>_, ok := chanrecv(c, v, true)
与发送消息一样,接受消息也会经过类似的几个过程:
- 1 . 守卫判断, 判断 ch 状态是否正常:
- 判断 ch 是否为 nil, 如果是则 使得当前 Goroutine 休眠,引发死锁崩溃
- 判断如果 (缓冲区没有信息且 发送队列也为空) 或 (缓冲区存在信息,但是信息为空); 在此同时若 ch 没有关闭 则直接返回空 实际上, 是因为 Channel 没有正常初始化
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
if c == nil { // 判断 ch 是否为空
if !block {
return
}
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
}
// 判断 ch 是否异常(没有正常的初始化)
if !block && (c.dataqsiz == 0 && c.sendq.first == nil ||
c.dataqsiz > 0 && atomic.Loaduint(&c.qcount) == 0) &&
atomic.Load(&c.closed) == 0 {
return
}
var t0 int64
if blockprofilerate > 0 {
t0 = cputicks()
}
lock(&c.lock)
}
- 2 . 上锁
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
lock(&c.lock) // 为 ch 上锁
...
}
- 3 . 若 ch 已经关闭则解锁退出并释放空间
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
if c.closed != 0 && c.qcount == 0 { // 若 ch 已经关闭则解锁退出
if raceenabled {...} // const raceenabled = false 所以不必理睬
unlock(&c.lock)A // 解锁
if ep != nil {
typedmemclr(c.elemtype, ep) // 释放 ch 缓冲区空间; 释放 ep 指针空间; (ep - 接收指针 : ep <- ch)
}
return true, false
}
...
}
- 4 . 若发送队列中存在
sudog(被封装的 阻塞 Goroutine), 则直接接受sudog中信息 并解锁退出
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
if sg := c.sendq.dequeue(); sg != nil { // 若发送队列中存在阻塞的 sudog
recv(c, sg, ep, func() { unlock(&c.lock) }, 3) // 直接接受并解锁
return true, true // 退出
}
...
}
- 5 . 若 ch 缓冲区 内存在信息,则通过缓冲区获得信息, 并解锁退出
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
if c.qcount > 0 { // 若 channel 的缓冲区存在信息
qp := chanbuf(c, c.recvx) // 通过接受索引 获取到 一个 发送信息的地址指针
if raceenabled { ... } // const raceenabled = false
if ep != nil { // 若 接受指针存在内存空间 则 qp 内存信息 复制给 ep
typedmemmove(c.elemtype, ep, qp) // 将 qp 指向的信息复制给 ep
}
typedmemclr(c.elemtype, qp) // 释放 qp 内存信息
c.recvx++ // 接受索引+1
if c.recvx == c.dataqsiz { // 若接受索引等于 ch 的 缓冲区大小,则置零
c.recvx = 0
}
c.qcount-- // 缓冲区内信息个数 - 1
unlock(&c.lock) // 解锁
return true, true // 退出
} ...
}
- 6 . 若 上述两种情形都不存在, 解锁 ch 并使得当前 Goroutine 陷入阻塞(
runtime.send将唤醒它) 并 加入 ch 接受队列
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
...
if !block { // 解锁当前 ch
unlock(&c.lock)
return false, false
}
gp := getg() // 获得当前 Goroutine 的指针
mysg := acquireSudog() // 创建 sudog
// 初始化 sudog (与 发送函数类似)
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep // 配置将接受指针指向的地址空间 交给 elem
mysg.waitlink = nil
gp.waiting = mysg // gp 设置成阻塞状态
mysg.g = gp // 将 sudog 装填 当前 Gorotuine
mysg.isSelect = false // 非 select
mysg.c = c // 装填 ch
gp.param = nil // 没有唤醒传参
c.recvq.enqueue(mysg) // 将 sudog 写入 ch 的接受等待队列
// 阻塞当前 Goroutine
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
// 唤醒后:
if mysg != gp.waiting { // 守卫:判断 gp.waiting 是否为当前线程的阻塞信息, panic
throw("G waiting list is corrupted")
}
gp.waiting = nil // 清空 gp 的 阻塞状态
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
closed := gp.param == nil //
gp.param = nil // 清空 gp 的 唤醒传参
mysg.c = nil // 清空 sudo 持有的 ch
releaseSudog(mysg) // 释放 sudog
return true, !closed // 退出
}
与 发送类似, 直接接受也调用了一个函数: runtime.recv
func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if c.dataqsiz == 0 { // 若 ch 缓存区 为空
if raceenabled {...} // const raceenabled = false
if ep != nil { // 若 ep 存在地址空间, 直接复制
recvDirect(c.elemtype, sg, ep) // 加锁; 复制内存
}
} else { // 从缓存区拷贝
qp := chanbuf(c, c.recvx) //通过 接受索引 获得 缓存区一条信息的地址空间指针 qp
if raceenabled {...} // const raceenabled = false
if ep != nil { // 若 ep 存在地址空间
typedmemmove(c.elemtype, ep, qp) // 将 qp 的信息赋给 ep
}
typedmemmove(c.elemtype, qp, sg.elem) // 将 发送 sudog 的 信息 赋值给 qp (缓冲区上的一个槽)
c.recvx++ // 接受索引+1
if c.recvx == c.dataqsiz { // 当接受索引等于缓冲区大小后置零
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
sg.elem = nil //清空 发送 sudog 携带的 信息
gp := sg.g // 获取 sudog 携带的 被阻塞的 Goroutine 指针 , 赋值给 gp
unlockf() // 解锁
gp.param = unsafe.Pointer(sg) // gp 传入取消阻塞传参 sg
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1) // 唤醒 gp (发送方被阻塞的 Goroutine)
}
可以看出 直接接受也是有顺序的,若 缓冲区存在有内容,会优先接受缓冲区的内容, 因为存在等待序列, 所以缓冲区是满的, 将缓冲区直接替换发送 sudog 的信息, 实现了先入先出
总的来看 Channel 接受也是三个步骤:上锁、接受信息、解锁
其中 接受信息 会出现4种情况:
- 如果存在正在阻塞的发送方,说明缓存已满,从缓存队头取一个数据,再将阻塞发送方的信息装入
- 如果没有阻塞的发送方 且 缓存区存在信息, 就从缓存区取出信息
- 没有能接受的数据,阻塞当前的接收方 Goroutine , 等待被唤醒
关闭 Channel
通常我们使用 close 关键字关闭 Channel, 而编辑器会将 close 转译成 runtime.closechan 函数的调用: close(ch) => closechan(ch)
closechan 由一下几个步骤实现:
- 1 . 守卫判断 channel 状态 ; 并上锁
func closechan(c *hchan) {
if c == nil { // 判断 ch 是否为空 ; panic
panic(plainError("close of nil channel"))
}
lock(&c.lock) // 上锁
if c.closed != 0 { // 判断 ch 是否已经被关闭
unlock(&c.lock) // 解锁 并 panic
panic(plainError("close of closed channel"))
}
if raceenabled { ... } // const raceenabled = false
...
c.closed = 1 // 给 ch 设置 释放标志
}
- 2 . 释放 Channel 的等待队列
func closechan(c *hchan) {
...
var glist gList // glist 存放因为接受或发送信息被阻塞的 Goroutine
for { // 循环释放
sg := c.recvq.dequeue() // 获取等待队列的 sudog
if sg == nil { // sudog 为 nil 退出循环体
break
}
if sg.elem != nil { // 若 sudog 接受数据的指针不为空(存在地址空间)
// 释放 sudog 的 接受数据指针的地址
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g // 取出 被阻塞的 Goroutine
gp.param = nil // 唤醒传参置为 nil
if raceenabled {...}
glist.push(gp) // Goroutine 压入 glist
}
...
}
- 3 . 释放 Channel 的发送队列
func closechan(c *hchan) {
...
for { // 循环释放
sg := c.sendq.dequeue() // 获取发送队列的 sudog
// 与释放接受队列类似
if sg == nil { // sudog 为 nil 退出循环体
break
}
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g // 取出 被阻塞的 Goroutine
gp.param = nil // 唤醒传参置为 nil
if raceenabled {..}
glist.push(gp) // Goroutine 压入 glist
}
...
}
- 4 . 解锁, 并唤醒所有被阻塞 Goroutine
func closechan(c *hchan) {
...
unlock(&c.lock) // 解锁 ch
for !glist.empty() { // 循环到 glist 全部被弹出
gp := glist.pop() // 弹出一个需要唤醒的 Goroutine
gp.schedlink = 0
goready(gp, 3) // 唤醒 Goroutine
}
}
总的来说 释放 经过了四个过程 :
- 加锁;
- 释放 Channel 的发送、接受缓冲区;
- 解锁;
- 唤醒所有被阻塞的 Goroutine
调度器
在调度器这节原作者讲述了调度器的发展历程 (0.x ~ 1.0 ~ 1.1 ~ 1.2 ~ 1.13 ~ 1.14 ~ 至今 and 非均匀存储访问调度器提案) 有兴趣的朋友可以去看看原文
而本文则从最新的版本入手学习, 最近一段时间学习翻了很多资料,又发现了一片不错的大佬文章: changkun 的 《 runtime.Goexit() 》 欢迎大家一起阅读学习。
Go 的调度机制由调度器( Scheduler ) 实现,它有三个重要的组件就是我们熟知的 MPG:
- M: Machine, 代表了机器资源,即 worker thread 、 工作线程。
- P: Processor, 处理者,一个抽象的中间层,用于调度 调度 Goroutine 在 I/O 时刻的切换。
- G: Goroutine: 我们熟知的 "Go 协程", 是 Go 语言执行任务的最小单位。(所有的 go func 都会被打包成
runtime.g)
每个 M 在执行代码之时都会持有一个 P, 而 P 持有一个 G 的队列, 并将需要执行的 G 交给 M 去执行。 P 的数量被调度器设定为 cpu核心数, 调度器会尽量将 P 分配给一个 系统线程去执行 P 携带的 G 的工作任务。当 M 执行的 G 发生 阻塞之后, 会创建一个新的 M, 并将 阻塞 M 携带的 P 交给
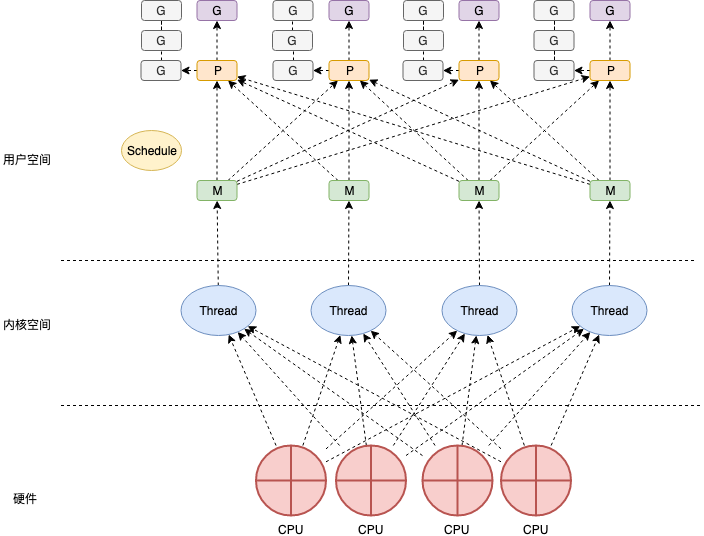
MPG 数据结构 (Scheduler 的构成)
原理讲来太空洞,我们先看一下 MPG 的数据结构, 通过其字段来窥探一下它们的作用。
mpg 的结构体都很大,定义了运行时的各种状态 (其中一部分是用来 debug),我们只从我们关心的部分入手。
先从我们最熟知的 G 开始:
G
type g struct {
stack stack // 执行栈, 描述了当前Goroutine 的栈内存范围 (lo ~ hi)
stackguard0 uintptr // 用于检测堆栈是否溢出(扩容或抢占)
stackguard1 uintptr // 用于检测C堆栈是否溢出
_panic *_panic // 指向 panic栈 最内测的对象
_defer *_defer // 指向 defer(延迟函数) 最内测的对象
m *m // 当前 Goroutine 占用的 M (可能为空)
sched gobuf // pc, sp, lr 等上下文数据
...
param unsafe.Pointer
stktopsp uintptr // sp期望栈顶, 用于回溯检查
param unsafe.Pointer // 唤醒时候传递的参数
atomicstatus uint32 // Goroutine 状态(_Gidle, _Grunnable, _Grunning ...)
stackLock uint32 // stack Lock
goid int64 // Goroutine Id 对开发者不可见,Go 团队认为引入 ID 会让部分 Goroutine 变得更特殊,从而限制语言的并发能力;
...
waitsince int64 // 阻塞的开始时间
waitreason waitReason // 阻塞的原因
preempt bool // 抢占信号
...
timer *timer // 为 time.Sleep 缓存的计时器
...
}
type stack struct { // 用于描述 Go 的执行栈
lo uintptr // 下边界
hi uintptr // 上边界
}
type gobuf struct { // 用于 保存、恢复 上下文
sp uintptr // 栈指针
pc uintptr // 程序计数器
g guintptr // 持有 gobuf 的 g 指针
ctxt unsafe.Pointer
ret sys.Uintreg // 系统调用的返回值
...
}
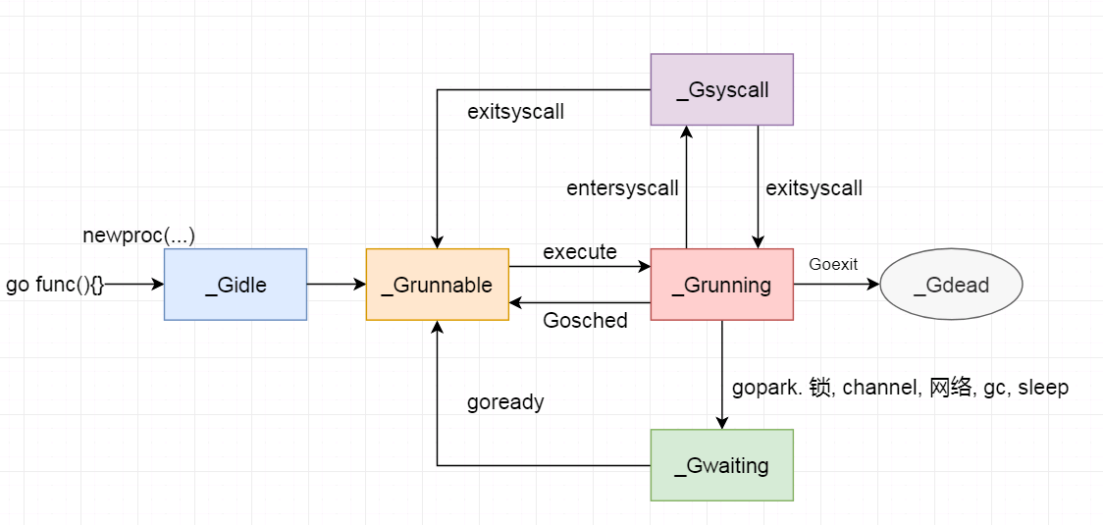
g 的 atomicstatus 存储了当前 Goroutine 的状态:
| 状态 | 值 | 说明 |
|---|---|---|
_Gidle |
0 | 刚分配, 尚未初始化 |
_Grunnable |
1 | 还没有被运行, 在runqueue上 |
_Grunning |
2 | 可能在执行, 拥有栈的所有权, 与M, P已绑定, 不在runqueue上 |
_Gsyscall |
3 | 执行系统调用, 没执行代码, 只与M绑定, 不在runqueue上 |
_Gwaiting |
4 | 被阻塞, 不在 runqueue 上, 但是可能在 Channel的等待队列、锁队列 上 |
_Gdead |
6 | 没有执行代码,也没有被使用,可能在被重新初始化 |
_Gcopystack |
8 | 栈正在被拷贝,没有执行代码,不在runqueue上 |
_Gpreempted |
9 | 由于抢占而被阻塞,没有执行代码,不在runqueue, 等待被唤醒 |
_Gscan |
0X1000 | GC 正在扫描栈空间, 没有执行代码, 可与其他状态同时存在 |
状态机:
M
M 代表了操作系统线程。调度器可以最多创建 10000 个线程, 但是其中大多数线程都不会执行代码(可能会陷入系统调用), 最多只会有 GOMAXPROCS 个活跃的线程能够正常运行。
默认情况下 GOMAXPROCS 会被设置成当前机器的核心数。而调度器也会启动 CPU 个数的 runtime.m, 最大化利用机器性能, 尽可能不让机器启动过多的线程而浪费了线程切换消耗的性能
(Goroutine 切换 比 线程切换 消耗性能低)。
接下来我们也来看看 runtime.m 的数据结构
type m struct {
g0 *g // m 持有的 Goroutine 用于执行调度指令
...
procid uint64 // 底层线程id (PID)
gsignal *g // 处理 signal 的 Goroutine
...
tls [6]uintptr // 本地线程存储 (传给 FS寄存器的线程局部存储)
mstartfn func() // m 启动时的函数
curg *g // 当前正在运行( 执行代码 ) 的 Goroutine
...
p puintptr // m 执行代码时持有的 p (没有执行代码时为 nil )
nextp puintptr // 暂存的 p
oldp puintptr // 执行系统调用之前使用 执行程序的 p
id int64 // id
spinning bool // m 没有可以执行的 g, 正在寻找可以执行的 g (自旋 spin); 其实 m 就两个状态 自旋(spinning) 和 运行(runing)
...
incgo bool // m 正在执行 CGO 调用
...
mcache *mcache // 运行代码是 绑定的 p 的 mache
...
}
g0 是一个运行时比较特殊的 Goroutine, 它会深度参与运行时的调度过程,包括 Goroutine 的创建,大内存的分配,CGO 函数的执行。
除了上面列出的字段, m 还存在着大量与线程状态,锁,调度,系统调用相关的字段。之后我们再具体介绍
m 也存在状态机, 相比 G P 要简单的多, 因为它就两种状态:

P
处理器 这个概念在 Go 最早的若干版本并没有被引入(最早 1.1版本引入)。 它是 m 与 g 的中间层,提供 m 需要的上下文环境, 也会负责调度 g 等待队列, 使得每个 内核线程都能够充分利用。 可以在 Goroutine 进行 I/O 操作时及时切换,提高线程的利用率。
调度器在启动时,就会创建 GOMAXPROCS 个p,这些处理 会绑定到不同的 m 上 ,充分利用机器性能。
下面我们也来看看 p 的字段
type p struct {
id int32 // p id
status uint32 // p 的状态; _Pidle, _Prunning...
...
m muintptr // 反向链接到关联的 m (nil 则表示 idle)
mcache *mcache // pre-p的分配cache
pcache pageCache // 页面缓存
...
deferpool [5][]*_defer // 不同大小的可用的 defer 结构池
deferpoolbuf [5][32]*_defer
runqhead uint32 // p 的运行队列头
runqtail uint32 // p 的运行队列尾
runq [256]guintptr// p 的运行队列
runnext guintptr // 下一个需要执行的 Goroutine
gFree struct {
gList
n int32
}
...
palloc persistentAlloc // per-P to avoid mutex
gcw gcWork
...
}
除了我们列出的, runtime.p 还包含性能追踪,垃圾回收,计时器相关的字段。
其 status 存储了 p 的状态:
| 状态 | 值 | 说明 |
|---|---|---|
_Pidle |
0 | 没有运行用户代码或调度程序,被空闲队列或者改变其结构的结构持有,runqueue为空 |
_Prunning |
1 | 被 M 持有, 正在执行用户代码或调度程序 |
_Psyscall |
2 | 没有执行用户代码,正在陷入系统调用 |
_Pgcstop |
3 | 被 M 持有, 当前 p 由于垃圾回收被停止 |
_Pdead |
4 | 当前处理器已经不被使用 |
P 状态机:
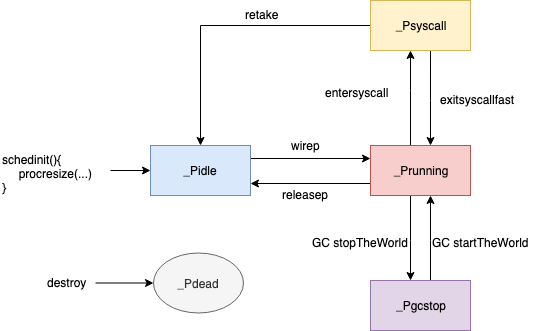
至此, 我们已经大致的了解了 Scheduler 中 MPG 的大致构成。接下来我们就分析分析 Scheduler 究竟是怎么运行的。
Scheduler 工作过程
Scheduler 启动
Scheduler 初始化, 我们逐一分析它的过程:
func schedinit() {
_g_ := getg() // 获取当前 Goroutine
if raceenabled { ... } // const raceenabled = false
sched.maxmcount = 10000 // 设置最大线程数 10000; Go 语言启动最大线程数为 10000
tracebackinit() // traceback 初始化
moduledataverify() // moduleData 验证
stackinit() // 堆栈初始化
mallocinit() // 内存分配初始化
fastrandinit() // 随机数模块初始化
mcommoninit(_g_.m) // M 初始化
cpuinit() // 初始化 cpu 相关的配置信息
alginit() // algebra(代数模块)初始化
modulesinit() // 初始化活跃的 模块
typelinksinit() // 初始化类型链接
itabsinit() // 初始化 itabs
msigsave(_g_.m) // 将信号遮码保存到 主线程 m
initSigmask = _g_.m.sigmask // 初始化信号遮罩
goargs() // 获得运行传参
goenvs() // 获得环境信息
parsedebugvars() // 解析调试变量
gcinit() // gc 初始化
sched.lastpoll = uint64(nanotime()) // 初始化上次网络轮训时间
procs := ncpu // P 数量设置成 cpu 数量
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 { // 如果有全局设置,则 P 数量设置为 GOMAXPROCS
procs = n
}
if procresize(procs) != nil { // 调整 P 的数量( P 初始化 )
throw("unknown runnable goroutine during bootstrap")
}
...
}
可以看到 schedinit 主要完成了程序变量的初始化,和一些 OS 相关模块的初始化, 其中定义了 Go 的最大线程数, P的默认个数等变量,
同时, M 的初始化 和 P 的初始化 是我们这里关注的重点。
M 初始化
在 Scheduler 初始化中,初始化 M 的 函数是 runtime.mcommoninit(), 下面我们来看看这个函数的执行过程:
func mcommoninit(mp *m) {
_g_ := getg() // 获得当前 Goroutine
if _g_ != _g_.m.g0 {
callers(1, mp.createstack[:]) // 如果 当前线程不是 M 的 g0, 创建堆栈
}
lock(&sched.lock) // 上锁
if sched.mnext+1 < sched.mnext { // 守卫: 判断 线程数是否溢出
throw("runtime: thread ID overflow")
}
mp.id = sched.mnext // 给 m 设置 id (实际上是当前 m 的创建序列)
sched.mnext++ // mnext ++
checkmcount() // 守卫: 判断 m 数量是否超过 限制(默认10000)
// 初始化 m 随机数
mp.fastrand[0] = uint32(int64Hash(uint64(mp.id), fastrandseed))
mp.fastrand[1] = uint32(int64Hash(uint64(cputicks()), ^fastrandseed))
if mp.fastrand[0]|mp.fastrand[1] == 0 {
mp.fastrand[1] = 1
}
mpreinit(mp) // 为 m 初始化一个 专门处理信号的 g
if mp.gsignal != nil {
mp.gsignal.stackguard1 = mp.gsignal.stack.lo + _StackGuard
}
// 添加到 allm 中,从而当它刚保存到寄存器或本地线程存储时候 GC 不会释放 g.m
// 这里 allm 指向最后一个 m ,它用于将新的 m 的 allink 引导指向 上一个 m, 在将 allm 指向最新的 m; 这样所有的 m 就链接起来了
mp.alllink = allm
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock) // 解锁
if iscgo || GOOS == "solaris" || GOOS == "illumos" || GOOS == "windows" { // 若 GC 奔溃, 分配内存保存 TraceBack
mp.cgoCallers = new(cgoCallers)
}
读完mcommoninit发现它只是对 m 进行了一个初步的初始化: 1.设置id; 2.创建 signal 处理 g ; 3. 链接到 allm; 尚未涉及到 线程处理工作。
P 初始化
在 schedinit中 P 的初始化 使用了 runtime.procresize 这个函数的本来用途是 调整 P 的数量。但在这里我们用作初始化 P 的个数:
func procresize(nprocs int32) *p {
old := gomaxprocs // 获得Go启动后 P 的最大数量数量
if old < 0 || nprocs <= 0 { // 守卫: 判断 p 数量是否异常
throw("procresize: invalid arg")
}
if trace.enabled { // 记录Trace事件
traceGomaxprocs(nprocs)
}
now := nanotime() // 获取当前系统时间
if sched.procresizetime != 0 { // 记录 p 总用时: (当前时间 - 上次更改 p 的时间) * p 数量 + 上次记录的总用时
sched.totaltime += int64(old) * (now - sched.procresizetime)
}
sched.procresizetime = now // 记录最后一次更改 p 数量的时间
// 该函数的主要部分 :更新 p 的数量
if nprocs > int32(len(allp)) { // 若预期 p 的数量大于当前运行的 p 的数量 (allp 是个切片)
lock(&allpLock) // 上锁
if nprocs <= int32(cap(allp)) { // 若预期 p 的数量 小于 allp 的容量(这里 allp 的容量大小是 程序执行至今 p 最多的时刻的 p 数量)
allp = allp[:nprocs] // 直接取切片(没有释放 多余 p 的空间)
} else { // 若 历史最大 P 数量 小于 预期 P 数量 :
nallp := make([]*p, nprocs) // 按照预期 P 的数量创建空间
copy(nallp, allp[:cap(allp)]) // 将 allp 直接复制到 新创空间中 (ps: 旧 P 已经初始化过)
allp = nallp // allp 指针指向 新创建的空间
}
unlock(&allpLock) // 解锁
}
// 遍历初始化需要新创建的 P
for i := old; i < nprocs; i++ { // 循环 需要创建的 P 的次数( 历史最大 P 数量 ~ 预期数量)
pp := allp[i]
if pp == nil { // 若 当前位置 nil,开辟空间创建 P 对象 (理论上应该都是 nil)
pp = new(p)
}
pp.init(i) // 初始化新创建的 p, (使用序列 i 作为 p 的 ID)
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp)) // &allp[i] 指向 pp
}
// 调整 p 的工作状态
_g_ := getg() // 获取当前 Goroutine
if _g_.m.p != 0 && _g_.m.p.ptr().id < nprocs {
// 若执行当前 G 的 M( 也可以说 线程; 个人还是倾向于 M 是 线程的指代/抽象) 存在 (m.p 是个 uintptr 默认值为 0),
// 且其ID小于预期 P 的数量, 则继续使用当前的 P
_g_.m.p.ptr().status = _Prunning // 更改 当前 P 状态 为 Running
_g_.m.p.ptr().mcache.prepareForSweep() // 清空页面缓存
} else { // 当前 M 不存在 P 或者 P 的 id 已经大于当前 P 规定数量
if _g_.m.p != 0 { // 当前 M 的 P 存在( 且序列已经超过预期 P 的个数 )
if trace.enabled { // Trace 记录 并 停止 P 执行
traceGoSched()
traceProcStop(_g_.m.p.ptr())
}
_g_.m.p.ptr().m = 0 // 清楚 预释放 P 的 m指针 (不能让 停止的 p 还携带 m)
}
// M 的 P 不存在( 或者刚刚被清楚了 )
_g_.m.p = 0 // 清空 当前 m 的 P 指针
_g_.m.mcache = nil // 清空当前 M 的 mcache (这个 mcache 实际上是从 P 中取到的)
p := allp[0] // 将 id = 0 的 p 交给 当前 M
p.m = 0 // 释放 这个 P 的 M 指针 ( id 为 0 的 P 不再为别的 M 服务了)
p.status = _Pidle // 重置 P 状态
acquirep(p) // 关联当前 P 和 M
if trace.enabled {
traceGoStart() // 记录 Trace 事件
}
}
for i := nprocs; i < old; i++ { // 遍历多余的 P
p := allp[i]
p.destroy() // 释放 P 的资源, 并将其转为 PDead
}
}
到此我们可以观察到 这个函数的主要工作 就是 调整 P 的数量, 在我们初始化 Scheduler 中用作: 保持 P 的数量为机器核心数。
而具体的 P 是如果 初始化的,procresize 调用了 runtime.p.init
func (pp *p) init(id int32) {
pp.id = id // 赋予 id
pp.status = _Pgcstop // 初始化 status
pp.sudogcache = pp.sudogbuf[:0] // 初始化 sudog 队列的 cache
for i := range pp.deferpool { // 初始化 defer 池
pp.deferpool[i] = pp.deferpoolbuf[i][:0]
}
pp.wbBuf.reset()
// 分配 cache
if pp.mcache == nil { // 若当前 p 没有 cache空间
if id == 0 { // 且是第一个创建的
if getg().m.mcache == nil { // 守卫: 验证当前 M 的 cache 不为空
throw("missing mcache?")
}
pp.mcache = getg().m.mcache // 当前(最早创建的) M 的 cache (引导空间) 交给 最早创建的 P
} else {
pp.mcache = allocmcache() // 分配新空间
}
}
if raceenabled && pp.raceprocctx == 0 { ... } // const raceenabled = false
}
runtime.p.init 主要是为 P 分配了各类的空间
G 初始化
我们并没有在 runtime.schedinit 中找到 G 初始化的蛛丝马迹, 实际上在我们代码中使用的 go 关键字, 会被 Go 编译器转换成 runtime.newproc
func newproc(siz int32, fn *funcval) { // siz 是参数长度, fn 是 go 执行的函数的引用指针
argp := add(unsafe.Pointer(&fn), sys.PtrSize) // 从 fn 的地址增加一个指针的长度,从而获取第一个参数的地址
gp := getg() // 获得当前 G
pc := getcallerpc() // 获得 pc 寄存器
systemstack(func() { // 使用系统堆栈调用下面的函数
newproc1(fn, argp, siz, gp, pc) // 创建 G
})
}
简单对传参进行加工,然后调用 runtime.newproc1
func newproc1(fn *funcval, argp unsafe.Pointer, narg int32, callergp *g, callerpc uintptr) {
_g_ := getg() // 获得当前 G
if fn == nil { // 守卫: 判断 fn 是否是 nil
_g_.m.throwing = -1
throw("go of nil func value")
}
acquirem() // _g_ := getg(); _g_.m.locks++; 禁止当前 m 被抢占因为它可以在一个局部变量中保存 p
siz := narg
siz = (siz + 7) &^ 7 // 8字节对齐。
if siz >= _StackMin-4*sys.RegSize-sys.RegSize { // 守卫: 穿参过大,超过内存控制范围
throw("newproc: function arguments too large for new goroutine")
}
_p_ := _g_.m.p.ptr // 当前 P
newg := gfget(_p_) // 通过 P 获得一个新 G
if newg == nil { // 如果 新 G 是空的
newg = malg(_StackMin) // 创建一个拥有 _StackMin 大小的栈的 g
casgstatus(newg, _Gidle, _Gdead) // 将新创建的 g 从 _Gidle 更新为 _Gdead 状态
allgadd(newg) // 将 Gdead 状态的 g 添加到 allg,这样 GC 不会扫描未初始化的栈
}
if newg.stack.hi == 0 { // 守卫: 判断 newg 拥有的栈大小是否没有初始化
throw("newproc1: newg missing stack")
}
if readgstatus(newg) != _Gdead { // 守卫: 判断 newg 的状态 是否是 _Gdead
throw("newproc1: new g is not Gdead")
}
// 计算运行空间大小,对齐
totalSize := 4*sys.RegSize + uintptr(siz) + sys.MinFrameSize // 计算程序需要的运行空间
totalSize += -totalSize & (sys.SpAlign - 1) // 对齐到 spAlign
sp := newg.stack.hi - totalSize // 确定 sp 入栈位置
spArg := sp // 确定 参数 入栈位置
if usesLR {
*(*uintptr)(unsafe.Pointer(sp)) = 0
prepGoExitFrame(sp)
spArg += sys.MinFrameSize
}
if narg > 0 { // 存在传参
memmove(unsafe.Pointer(spArg), argp, uintptr(narg)) // 将传参的内容,复制到 新 G 的执行栈
if writeBarrier.needed && !_g_.m.curg.gcscandone { // 如果当前写屏蔽开启, 并且当前 G 的堆栈尚未被 GC 扫描
f := findfunc(fn.fn) // 通过原方法的指针(开辟新的空间)构建方法对象(funcInfo)
stkmap := (*stackmap)(funcdata(f, _FUNCDATA_ArgsPointerMaps)) // 将新创建的方法对象指针封装成栈映射对象(stackmap)
if stkmap.nbit > 0 { // 若栈映射对象的索引大于 0
bv := stackmapdata(stkmap, 0) // 获取堆栈第0位的位向量
bulkBarrierBitmap(spArg, spArg, uintptr(bv.n)*sys.PtrSize, 0, bv.bytedata) // 重新将参数复制到 G 的执行栈
}
}
}
// 清理、创建并初始化的 g 的运行现场
memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched)) // 清空 新创建的 G 的运行现场
newg.sched.sp = sp // 初始化 运行现场的 sp 偏移量
newg.stktopsp = sp // 初始化 sp 堆顶偏移量
newg.sched.pc = funcPC(goexit) + sys.PCQuantum // 初始化 pc 偏移量
newg.sched.g = guintptr(unsafe.Pointer(newg)) // 初始化 调度信息的 g (newg 获取指针 给 sched.g)
gostartcallfn(&newg.sched, fn) // 根据 fn, 系统信息 调整 sched 的 sp, pc, ctxt
// 初始化 newg 的状态
newg.gopc = callerpc // 新 G 继承 当前 G 的 pc
newg.ancestors = saveAncestors(callergp) // 当前 G 封装成 []ancestorsInfo 赋值给 ancestors (祖先 g 列表)
newg.startpc = fn.fn // 当前 G 的初始 PC 指向 fn的地址
if _g_.m.curg != nil { // 若当前 M 运行的 G 不为空:
newg.labels = _g_.m.curg.labels // 新 G 继承 当前 M 运行的 G 的 标签
}
if isSystemGoroutine(newg, false) { // 若 新创建的 g 是 System Goroutine 运行现场的系统g统计 + 1
atomic.Xadd(&sched.ngsys, +1)
}
casgstatus(newg, _Gdead, _Grunnable) // 完成 newg 初始化, 转为 _Grunable 状态
// 分配 goid
if _p_.goidcache == _p_.goidcacheend {
_p_.goidcache = atomic.Xadd64(&sched.goidgen, _GoidCacheBatch)
_p_.goidcache -= _GoidCacheBatch - 1
_p_.goidcacheend = _p_.goidcache + _GoidCacheBatch
}
newg.goid = int64(_p_.goidcache)
_p_.goidcache++
if raceenabled { ... } // const raceenabled = false
if trace.enabled { // 记录 Trace 事件
traceGoCreate(newg, newg.startpc)
}
runqput(_p_, newg, true) // 将这里新创建的 g 放入 p 的本地队列或直接放入全局队列
// 如果有空闲的 P、且 spinning 的 M 数量为 0,且主 goroutine 已经开始运行,则进行唤醒 p
if atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0 && mainStarted {
wakep()
}
releasem(_g_.m) // 为 M 解锁 (回应 函数开头防止 M 被抢占上锁)
}
newproc1 这个函数十分复杂, 大概步骤总结下来:
- 获得一个
_Gdead状态的 g:- 首先尝试从 P 本地 gfree 链表或全局 gfree 队列获取已经没有用的(
_Gdeaad状态的) g (gfget(_p_)) - 初始化过程中程序无论是本地队列还是全局队列都不可能获取到 g,因此创建一个新的 g,并为其分配运行线程(执行栈),这时 g 处于 _Gidle 状态
- 首先尝试从 P 本地 gfree 链表或全局 gfree 队列获取已经没有用的(
- 创建完成后,g 被更改为 _Gdead 状态,并根据要执行函数的入口地址和参数,初始化执行栈的 SP 和参数的入栈位置,并将需要的参数拷贝一份存入执行栈中
- 根据 SP、参数,在 g.sched 中保存 SP 和 PC 指针来初始化 g 的运行现场
- 将调用方、要执行的函数的入口 PC 进行保存,并将 g 的状态更改为 _Grunnable
- 给 goroutine 分配 id,并将其放入 P 本地队列的队头或全局队列(初始化阶段队列肯定不是满的,因此不可能放入全局队列)
- 检查空闲的 P,将其唤醒,准备执行 G,但我们目前处于初始化阶段,主 goroutine 尚未开始执行,因此这里不会唤醒 P。